1. buffer pool 介绍
InnoDB存储引擎使用了 buffer pool 内存缓冲区来提升性能 ,buffer pool 是一块内存区域,是基于内存的一个组件,也是我们必须要搞清楚的核心组件,它里面缓存了磁盘的 数据页 上真实的数据;
我们对于 数据库 的增删改查的操作,不会直接跟磁盘打交道,而是在 buffer pool 上进行,然后配合 undo log、redo log、binlog、刷盘机制 等一起来实现了数据写入流程;
buffer pool 的读写操作:
- 读操作:如果要读的数据页在内存 buffer pool 中时,就直接从内存中读取后返回;不在buffer pool时,就先从磁盘中把数据页读取到buffer pool,再返回;
- 写操作:如果要更新的数据页在 内存buffer pool中时,就直接更新内存;数据不在内存中时,不会直接从磁盘中加载数据页到 buffer pool 中,而是记录到 change buffer 中;
2. buffer pool 结构
2.1 几个概念
数据页:
数据库中的核心数据模型一般为:表 + 行 + 字段;也就是说 数据库里面有一个一个的表,表里面有很多行数据,一行数据里面有很多的字段;
但是这些数据行,并不是直接一行一行的放在 buffer pool 中的,而是被抽象和组织 成了 数据页 的概念;它是把很多行数据放在一个数据页里,以数据页为单位来存储,磁盘文件中有多个数据页;
默认情况下,数据页 的大小是 16KB,其中包含了 很多元数据 和 实际的数据行;
缓存页:MySQL 在执行的时候,会把 磁盘 中的数据页加载到内存 buffer pool 中;所以在 buffer pool 中就划分出来了缓存页,缓存页跟数据页一一对应,也是 16KB;
缓存页的元数据:对于每个缓存页,都有一个元数据结构(也就是描述信息);这个元数据中包含了这个缓存页中:加载的数据页所属的表空间、数据页的编号、缓存页在 buffer pool 中的位移地址、组成各种链表的指针 等;
2.2 初始化 buffer pool
在 MySQL 启动的时候,会按照 buffer pool 的参数(innodb_buffer_pool_size)的大小,申请一块内存区域;
申请好之后,会按照 16KB 的缓存页大小 + 800byte 左右的元数据结构大小,在 buffer pool 中划分出一个个的缓存页以及对于的元数据;其中所有元数据在前面一起,缓存页在后面;
大概结构为: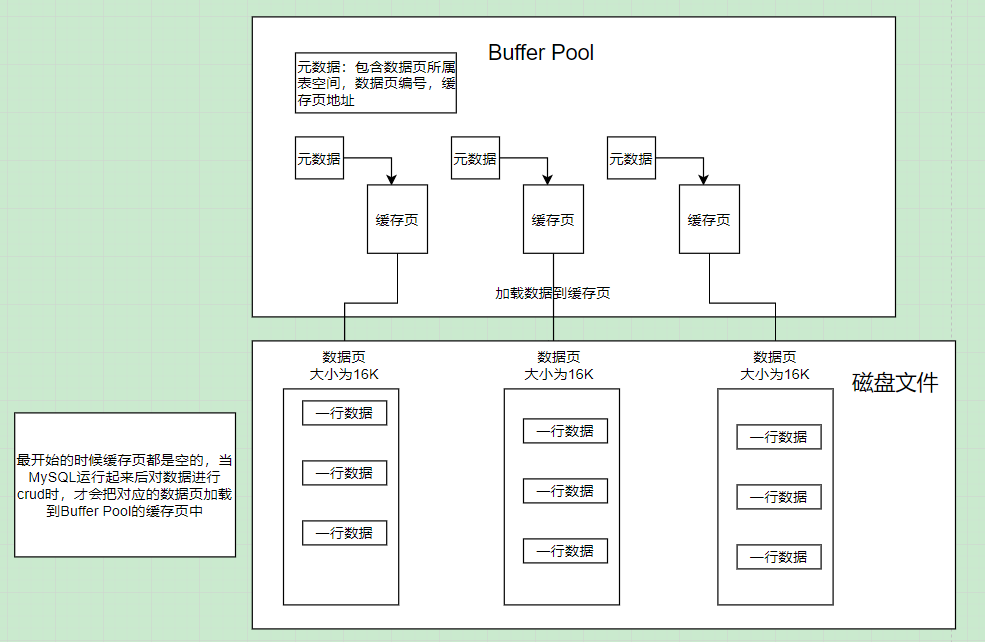
最初的缓存页都是空的,当MySQL运行起来之后,对数据执行 增删改查,就会执行以下一系列操作:
- 数据页加载到缓存页;
- buffer pool 中被修改过的缓存页(也就是脏页),会被线程定时刷入到磁盘中的数据页(刷脏);
- 当 buffer pool 中缓存页满时,又会进行淘汰一些缓存页,淘汰的时候也要刷脏;
这些操作都是一个动态的过程,随着 MySQL 的运行(也就是SQL语句的执行)来动态演变的;
下面就来看看这些动态演变的过程:
当进行CRUD操作时,需要把数据页加载到缓存页中,此时就需要知道哪些缓存页是空的,
怎么知道哪些缓存页是空的?
MySQL为此设计了一个Free链表,本质是一个双向链表,每个节点都是一个缓存页的元数据
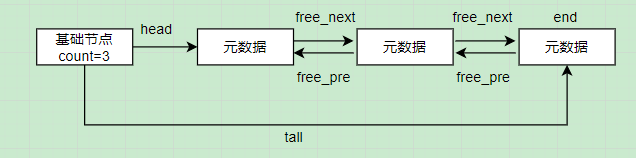
使用free链表将所有空闲缓存页的元数据连接起来,free_next 和free_pre是元数据的两个属性,使用一个基础节点来连接头尾节点,并记录有多少个空闲节点;
所以当需要加载一个数据页到Buffer Pool时,(1)首先从free链表中获取一个元数据节点,(2)再找到对应的空闲缓存页,就可以将数据加载到缓存页中了,(3)最后再把元数据从free链表中删除。
那么在加载数据页时怎么知道缓存页中是否缓存过了呢?
MySQL为此设计了一个哈希表的数据结构
| key | value |
|---|---|
| 表空间编号1+数据页编号1 | 缓存页地址1 |
| 表空间编号1+数据页编号2 | 缓存页地址2 |
| … | … |
当需要使用某个数据页时,就用数据页所属的表空间编号+数据页编号到哈希表中查询,如果能够查到,就使用value对应的缓存页;如果查询不到就将此数据页加载到缓存页中,并更新哈希表。
缓存页中的数据仅用于查询,操作结束时缓存页与数据页中的数据一致;当进行其它操作时,缓存页与数据页中的数据不一致,这些缓存页我们称之为脏页,而只有脏页才需要写回磁盘中;
那么如何确定哪些缓存页是脏页呢?
MySQL为此设计了一个flush链表,本质上也是一个双向链表,每个节点都是一个缓存页的元数据
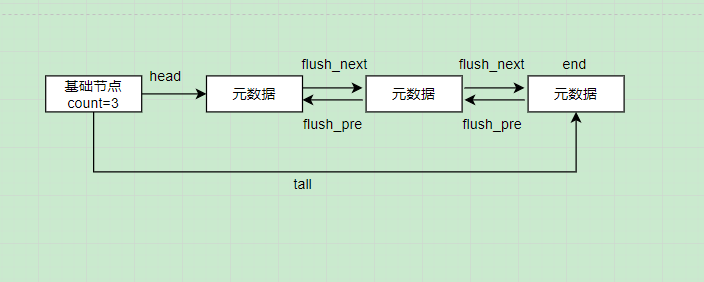
同样,flush_next与flush_pre都是元数据中的两个属性;flush链表最初是空的,当缓存页被更新时,就把缓存页对应的元数据加入到flush链表,此时当前缓存页就被标识为脏页;
随着服务的不断运行,大量的数据页被加载到Buffer pool中,free链表节点越来越少,那么总有一个时候没有空闲缓存页
(如果一个查询语句要加载的数据页很多,那么淘汰的脏页也就越多(需要先刷脏再加载),会导致查询的响应变慢(MySQL抖动))
那么这个时候该淘汰哪些缓存页呢?
MySQL采用LRU算法,并为此设计了一个LRU链表,本质上还是一个双向链表,每个节点都是一个缓存页的元数据
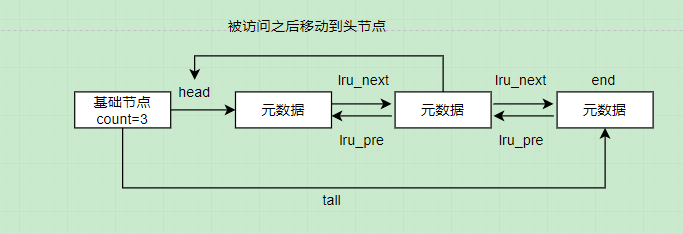
lru_next与lru_pre都是元数据中的两个属性
当一个数据页被加载到Buffer Pool时,会将缓存页对应的元数据放到lru链表的头部;当某个缓存页被访问时,也将该缓存页对应的元数据放到lru链表的头部;这样最近频繁使用的缓存页都在链表头部,长时间未使用的缓存页在链表尾部,当需要淘汰一个缓存页时,直接淘汰了尾部节点对应的数据页即可。
简单LRU链表的隐患
MySQL预读机制(减少磁盘IO)
- 线性预读:当顺序的访问了一个区(extent)中的56个数据页(innodb_read_ahead_threshold)时,会把相邻的区中的所有数据页都加载到Buffer Pool中;
- 随机预读:当Buffer Pool中缓存了一个区中13个连续的数据页时,就会把这个区中剩下的数据页加载到Buffer Pool中。
对于一个大表的全表扫描会把所有的数据页都加载到Buffer Pool中
这两种情况都会导致大量的数据页被加载到Buffer Pool中,并且会放到lru链表的头部,这些数据可能被访问一次之后再也不被访问了;
而以前的热点数据被挤到lru链表的尾部,可能会被直接淘汰,后续被访问时又需要将这部分数据从磁盘加载进来,减少了效率,并且双向链表的频繁移动也会造成不必要的资源浪费。
因此MySQL没有采用简单的LRU算法实现LRU链表,而是采用冷热数据分离的方式。LRU链表会被分为两个部分,热数据部分(young区域)和冷数据部分(old区域)。每个部分所占的比例可以通过innodb_old_blocks_pct参数来指定,默认为37,意思是冷数据占比3:7
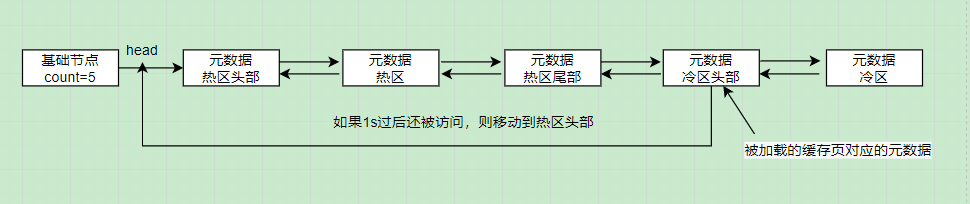
基于冷热数据区分离的LRU链表
工作原理:
- 数据页第一次被加载到Buffer Pool中时,对应的元数据放置在冷数据区的头部,
- 过了1s之后(innodb_old_blocks_time,默认为1000ms),这个缓存页再次被访问了,才会被移动到LRU链表的头部,(降低调整LRU链表的频率,从而提升性能)。
- 这样一来,冷数据区保存的都是一些被预读、全表扫描进来的只需访问一次的数据,而热数据区保存的都是一些被频繁访问的数据,此时淘汰的都是冷数据区尾部的数据,不会对热点数据的访问造成影响。
进一步优化
对于热数据区,如果缓存页一被访问就马上移动到头部,也会降低MySQL的性能(热点数据都是被频繁访问的,频繁移动元数据节点 也会消耗大量资源)
MySQL对此的优化方案:只有当热数据区后3/4的数据被访问了,才会移动到头节点,前1/4的缓存页被访问则不移动,这样减少了链表节点的移动。
Redis中的LRU淘汰
Redis也存在单次扫描或查询操作加载过多的数据,从而造成缓存污染,对于这种情况,Redis采用的是LFU算法(基于访问频次淘汰,而不是基于最近访问时间)
刷脏机制
- MySQL后台存在一个io线程,会定时将LRU链表冷数据区尾部的几个元数据节点对应的缓存页刷回磁盘,并清空缓存页放入free链表,并不会等到没有空闲缓存页之后再去刷盘
- 后台io线程在MySQL不繁忙时,将flush链表中的缓存刷入磁盘,并放入free链表
CRUD执行的动态过程
随着CRUD操作的不断进行,free链表节点不断消耗,LRU链表不断地增加和移动,flush链表也不断地增加,同时后台io线程不断地是刷盘,使得LRU链表与flush链表中的节点不断地减少,归还到free链表中。
多个Buffer Pool优化并发能力
当多个线程同时访问Buffer Pool时,都需要去访问缓存页、元数据、各种链表等共享的数据结构;由于线程安全问题,所以必然要加锁来保证数据的安全性,性能也会随之下降;
MySQL提供了多个Buffer Pool的设计来应对高并发访问:
1.Buffer Pool Size小于1GB时,最多分配一个Buffer Pool;
2.如果并发很高则需部署在大内存的服务器上,并给Buffer Pool分配较大的内存,同时指定Buffer Pool的个数,例如个Buffer Pool分配8GB的内存,设置4个Buffer Pool,那么每个Buffer Pool Size为2GB
innodb_buffer_pool_size(默认为128m)=8589934952 innodb_buffer_pool_instances=4
Buffer Pool基于chunk机制来支持运行期间动态调整大小
Buffer Pool是由多个chunk组成的,chunk由innodb_buffer_pool_chunk_size控制,默认为128m,例如上面2GB大小的Buffer Pool是由16个128m的chunk组成
每个chunk都包含了各自的缓存页和元数据,但是它们共享一套free链表、flush链表、LRU链表
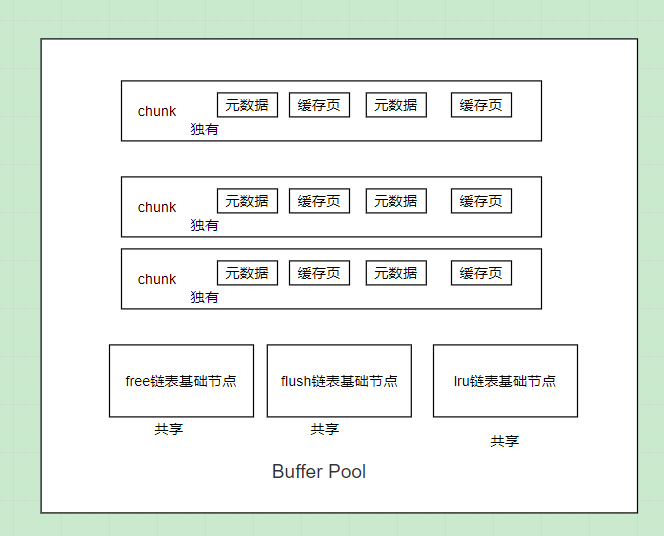
当要调整Buffer Pool大小时,例如将2GB的Buffer Pool调整为4GB,只需申请一系列的chunk分配给Buffer Pool即可
