以⼀个Update语句,了解InnoDB引擎的架构设计
1.buffer pool读写操作
InnoDB存储引擎使⽤了buffer pool内存缓冲区来提升性能;
- 读操作:如果要读的数据⻚在内存buffer pool中时,就直接从内存中读取后返回;不在buffer pool
时,就先从磁盘中把数据⻚读取到buffer pool,再返回;
- 写操作:如果要更新的数据⻚在内存buffer pool中时,就直接更新内存;数据不在内存中时,不会
直接从磁盘中加载数据⻚到buffer pool中,⽽是记录到change buffer中;
2.change buffer
这⾥先简单介绍⼀下change buffer:
change buffer:是⼀个可以持久化的数据,⾸先是存在于内存,但是也会被写⼊到磁盘;
原理:
- 如果要更新的数据⻚不在内存中,InnoDB会将这些更新操作先写到change buffer中,这样就不需要从磁盘中读⼊这个数据⻚再进⾏更新了;
- 在下次查询需要访问到这个数据⻚,或者后台线程定时执⾏时;会进⾏merge操作,将change buffer中的内容merge到buffer pool中对应的数据⻚中;
好处:更新的时候,先将更新操作记录在change buffer,减少读磁盘,这样语句的执⾏速度会得到明显的提升(减少随机IO的访问);
- 另外,数据读⼊内存是要占⽤buffer pool的,这样也可能淘汰⼀些使用率不高的热数据,降低内存占⽤率;
- 在merge的时候,change buffer中记录的变更越多,收益就越⼤;(因为减少了很多的磁盘读取)
适⽤场景:
- (适合)写多读少的业务;
- 数据⻚在写完之后⻢上被访问的概率⽐较⼩,所以此时change buffer的使⽤效果最好;常⻅业务模型为账单类、⽇志类系统;
- (不适合)写后⻢上就做查询的业务;
- 如果写了之后⻢上就会做查询,将更新先记录在change buffer,但由于⻢上就要访问,就会⽴即触发merge过程;这样随机访问IO不会减少,反⽽增加了维护change buffer的代价;
- (适合)写多读少的业务;
⼤⼩设置:
- changebuffer使⽤的是buffer pool的内存,因此不能⽆限增⼤;
- 通过参数innodb_change_buffer_max_size来动态设置;这个参数设置为50的时候,表示最⼤能占⽤buffer pool的50%;
3.WAL(Write-AheadLogging)
WAL:Write-AheadLogging;先写⽇志,再写磁盘(数据真实写到磁盘的数据⻚上);
当要更新⼀条记录的时候,不会直接更新磁盘上的数据;
- ⽽是先更新内存中的数据,然后为了避免崩溃会把更新的数据写⼊到⼀个⽇志⽂件中;
- 然后InnoDB引起在适当的时候,将内存中的数据刷新到磁盘中持久化;
这⾥可能会有⼀个疑问:将更新的数据写⼊到⽇志⽂件中,不也是写了⼀次磁盘?为什么不将数
据直接就写到磁盘?这⾥就涉及到⼀个概念:顺序IO和随机IO;
○顺序IO:指读写操作的访问地址连续,所以顺序IO的性能很好;(⼀般数据备份、写⽇志等是顺序IO)
○随机IO:读写操作的的访问地址不连续,随机分布在磁盘的地址空间中,所以可想⽽知随机IO的性能很差;(⼀般SQL⽂件是随机IO)
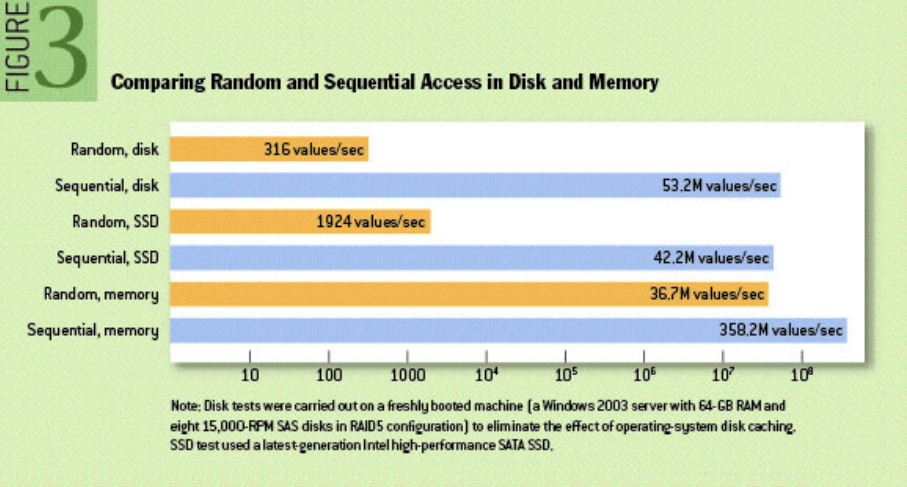
从这个对⽐图中可看出,差距基本在⼏个数量级以上
所以,MySQL这样设计的⽬的就是:
如果更新操作直接去更新磁盘上的数据⽂件,将会是随机IO,性能⾮常差;
当只更新内存,然后去写到redolog⽇志⽂件中;此时写⼊执⾏的是顺序IO,性能很好;
4.InnoDB更新流程
这⾥就简单⼀点,省略掉change buffer的应⽤和merge的过程,近似看做:
当要更新的数据⻚不在内存buffer pool中时,先从磁盘中将数据⻚读到bufferpool中,再更新内存中的数据⻚;
InnoDB存储引擎使用Buffer Pool缓冲区提升性能:
- 读操作:如果读取的数据页在Buffer Pool中直接返回;不在时,则在磁盘中查询,并将数据页加载到BufferPool中,再返回。
- 写操作:若需要更新的数据页在Buffer Pool中直接更新BufferPool中的数据页;不在时,从磁盘中加载数据页,再更新
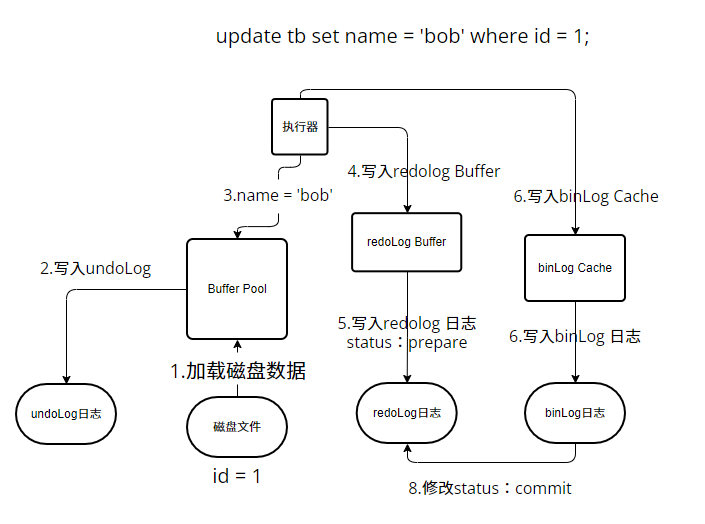
1.更新时,这条记录所在的数据页不在Buffer Pool中,则先将数据页加载到Buffer中
2.维护undoLog日志,InnoDB为了支持事务回滚,先把原来的的数据记录到undoLog日志(逻辑日志),具体体现为delete操作时写入insert语句,发生回滚时执行insert
3.更新BufferPool中的数据,此时BufferPool中name=’bob’,磁盘中name=”fox”,数据不一致,BufferPool中这行数据为脏数据,所在数据页为脏页
4.若此时发生宕机,Buffer Pool中数据丢失,破坏了一致性,所以在执行上述操作时,应将脏页写入redoLog中,在MySQL恢复后更新磁盘中的数据。
WAL机制:先写日志再写磁盘,为提升效率,MySQL提供了redolog Buffer,在事务提交时根据策略刷入。
5.事务提交时,redolog Buffer刷盘策略(Innodb_flush_log_at_trx_commit):
0:每次事务提交时,数据都只存在redoLog Buffer中,不刷入磁盘(MySQL宕机可能会丢失数据)
1:每次事务提交时,数据把redolog Buffer的数据刷入磁盘(MySQL不会丢失数据)
2:每次事务提交时,数据把redolog Buffer的数据刷入OS Cache,而不是写入磁盘,所有速度很快,效率基本接近0的配置(仍可能丢失数据)
6.事务提交时除了写入redoLog还会写入binLog(归档日志)
binLog是逻辑日志,记录的是原始SQL
binLog三种格式:
- 1:Statement每一条会修改数据的sql都会被记录在binlog中
优点:不需要记录每一行的变化,减少了binlog日志量,节省了IO,提高性能
缺点:由于记录的只是执行语句,为了这些语句能在slave上正常执行,因此还必须记录每条语句执行时的相关信息,以保证所有语句能在slave得到和master端执行时相同的结果。另外mysql的复制,像一些特定函数功能,slave可与master上要保持一致会有很多相关问题(如sleep()函数、last_inster_id()、以及userr-definedfunctions(udf)会出现问题),以下操作也会出现问题:
原始:
id name time
1 a 2022-06-0100:00:00
2 b 2022-06-0300:00:00
update tb set name="bob" where `order` > 1 and time < "2022-07-0100:00:00" limit 1
id和time字段都有索引,这条SQL可能在主库执行时使用order索引,更新了id=1这条记录,但是在从库使用的是time这个索引,更新的是id=2这条记录,主从不一致的问题就产生了。
主库
id name time
1 bob 2022-06-0100:00:00
2 b 2022-06-0300:00:00
从库
id name time
1 a 2022-06-0100:00:00
2 bob 2022-06-0300:00:00- 2.ROW:不设置sql语句上下文相关信息,仅保存哪条记录被修改(最常用)
优点:binlog中可以不记录执行的sql语句的上下文相关的信息,仅需要记录哪一条记录被修改成什么,所以rowslave的日志内容会非常清楚的记录下每一行数据修改的细节,而且不会出现某些特定情况下的存储过程,或function,以及trigger的调用和触发无法被正确复制的问题
缺点:所有执行的语句当记录到日志中时,都将以每行的记录来记录,这样可能会产生大量的日志内容,比如一条update语句,修改多条记录,则binlog中每一条修改都会被记录,这样造成binlog的日志量会很大,特别是当执行altertable之类的语句时,由于表结构修改,每条记录都发生变化,那么该表每一条记录都会记录到日志中。
3.MiXED:是以上两种level的混合使用
一般的语句修改使用Statement格式保存binlog,如一些函数,statement无法完成主从复制的操作,则采用ROW格式保存binlog。mysql会根据执行的每一条具体的sql语句来区分对待记录的日志形式,也就是从Statement和ROW中之间选择一种。新版本的mysql中对ROW模式也做了优化,并不是所有的操作都会以ROW格式记录,像遇到表结构变更的时候就会以Statement模式来记录,至于update和delete等修改数据的语句还是会记录所有行的变更。
binLog属于Server层而不是InnoDB引擎的日志,主要作用是归档,用于数据恢复、主从同步等。
同样也提供了binlog Cache(基于内存,每个线程一个),在事务提交时,根据策略(sync_binlog)将Cache中的数据刷入binLog文件中:
0:每次提交事务都只写入(Write)文件系统的OSPageCache,而不执行数据持久化到磁盘中(Fsync)
1:每次提交事务都会执行Fsync
N:(N>1)每次提交事务都只执行Write,积累到n个事务之后再执行Fsync
7.基于redoLog和binLog的二阶段提交(保证数据一致性)
在第5步写入的redoLog状态为prepare,等到binLog也写完之后,再将redoLog的状态修改为commint,只有在redoLog状态为commit时,才会认为本次事务执行成功(保证redoLog和binLog数据一致性,主要保证主从数据一致性)
8.刷脏:在经过第3步之后,内存中的数据与磁盘中的数据不一致了,后台有一个IO线程会在系统相对空闲的时间,将BufferPool中的数据落盘
innodb_io_capacity:参数定义了InnoDB后台任务每秒可用的I/O操作数(IOPS)
补充:
上⾯说到,数据写到buffer pool之后,要写到redolog中;但是也不是直接写⼊到redolog⽇志⽂件
中的,⽽是写⼊到redolog buffer中的,⽽redologbuffer中的数据是在事务提交的时候才刷⼊到磁
盘中;如果这个时候,事务还没有提交,MySQL服务器就崩了,那会不会导致数据丢失?
⾸先,内存buffer pool中的数据肯定没有了,然后redolog buffer中的数据也没有了;那这个时候算是
数据丢失吗?
其实是不算的,因为事务都没有提交,就代表你这条语句没有执⾏成功,语句都没有执⾏成功,那肯定你所有想要的结果都不能算数;
但是在事务还没有提交时,redolog buffer中的数据是有可能被持久化到磁盘中的:
InnoDB后台有⼀个线程,每隔1s就会把redolog buffer中的数据,调⽤write写⼊到page cache中,然后再调⽤fsync持久化到磁盘的redolog⽇志⽂件中;redolog buffer占⽤的空间即将达到innodb_log_buffer_size⼀半的时候,后台线程会主动写
盘(write);并⾏的事务提交的时候,顺带将这个事务的redolog buffer持久化到磁盘;(假设⼀个事务A执⾏到⼀半,已经写了⼀些redolog到buffer中,这时候有另外⼀个线程的事务B提交,如果innodb_flush_log_at_trx_commit设置的是1,那么按照这个参数的逻辑,事务B要把redolog buffer⾥的⽇志全部持久化到磁盘。这时候,就会带上事务A在redolog buffer⾥的⽇志⼀起持久化到磁盘)
,

