MySQL索引应⽤介绍
1. 索引分类
MyIsam 存储引擎中索引的存储格式
在MyIsam中,也是通过B+树作为索引的数据结构,但是跟InnoDB不同的是,MyIsam的索引⽂件和数据⽂件是分开的,使⽤.MYI来表示索引⽂件,使⽤.MYD来表示数据⽂件,那主键索引的结构为:
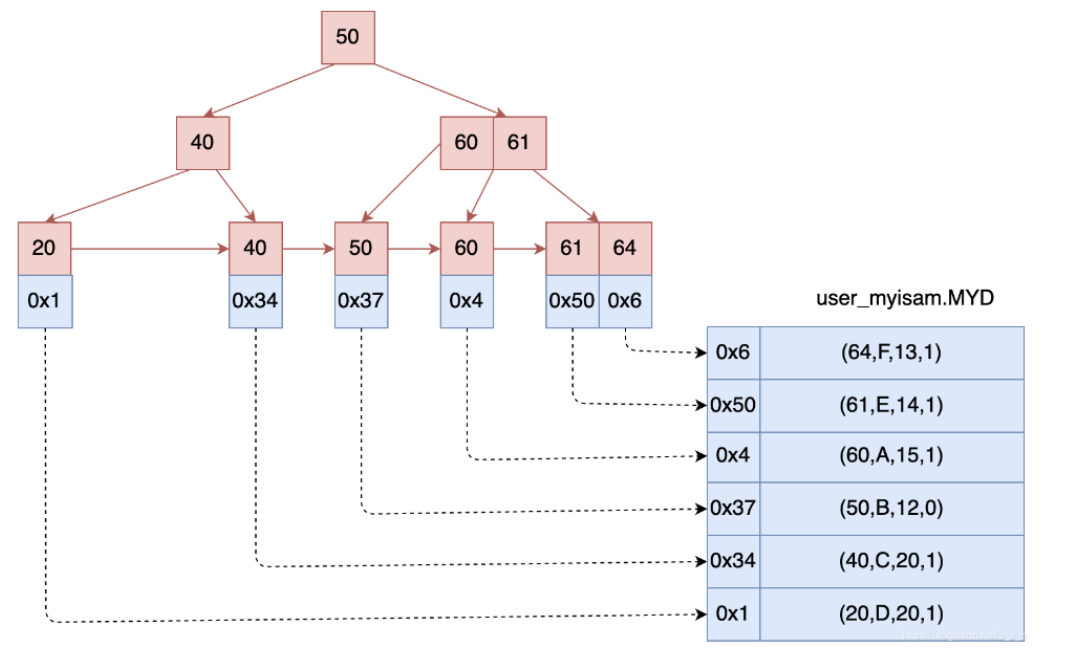
可以看到,MyIsam索引的中间节点的组织⽅式,跟InnoDB相同,也是只存储指向的数据⻚的指针和指向的数据⻚中的最⼩id;但是叶⼦节点就不同了:
- InnoDB的索引树中叶⼦节点中,存储了记录⾏的所有的数据信息,也就是有所有数据;
- MyIsam的索引树中叶⼦节点中,只存储了指向的数据⽂件中的指针位置,需要到数据⽂件中去找到具体的记录⾏的数据信息;
既然主键索引的叶⼦节点中是指针指向的数据⽂件中的具体的数据信息,那⾮主键索引肯定也就没有区别了,也是通过叶⼦节点来指向数据⽂件:
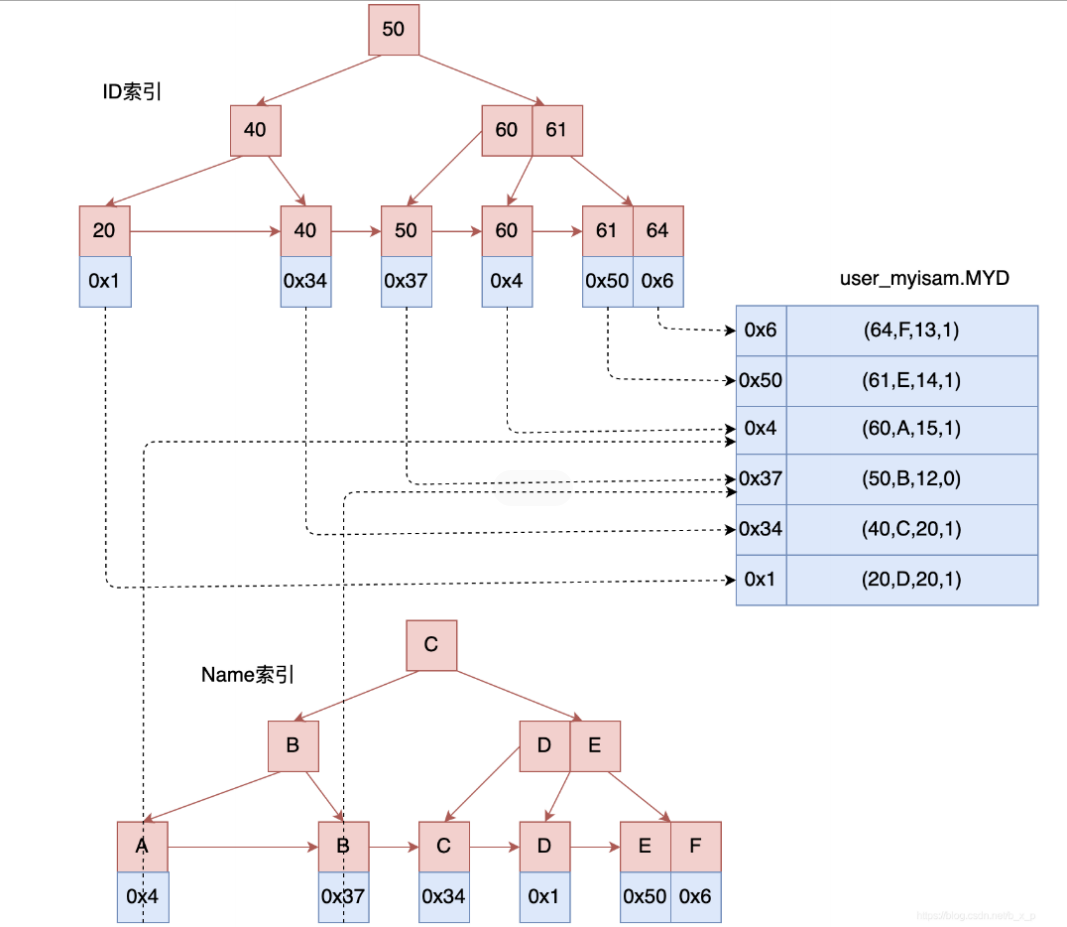
根据InnoDB和MyIsam 这两种存储⽅式,就可以总结出索引的第⼀种分类了;
1.1聚簇索引与⾮聚簇索引
- 聚簇索引:数据和索引结构是存放在⼀起的;
- 也就是对于⼀个表的数据它的索引项的逻辑顺序与表中记录在磁盘上的物理顺序是⼀致的(因为他们就是存放在⼀起的),也就是索引就是数据,数据就是索引;
- 聚簇索引⼀般就只有InnoDB的主键索引;
- ⾮聚簇索引:数据和索引结构没有存储在⼀起;
- ,数据结构是在⼀个⽂件中,索引结构是在另外⼀个⽂件中;
- 对于⼀个表的数据,它的索引项的逻辑顺序与表中记录在磁盘上的物理顺序是不⼀致的;
- ⾮聚簇索引⼀般有MyIsam的所有索引、InnoDB的普通索引
1.2 InnoDB的主键索引和普通索引
主键索引:在InnoDB中,对于每个表都会根据主键ID来创建⼀个主键索引;特征:
- 数据⻚中的所有记录⾏都按照主键ID⼤⼩排列,组成⼀个单向链表;
- 索引树中的所有数据⻚和索引⻚都按照⻚中记录的最⼩项ID的⼤⼩来排列,组成⼀个双向链表;
- 索引树中的叶⼦节点是数据⻚,⾥⾯有完整的记录⾏的数据信息;⽽⾮叶⼦节点是索引⻚,⾥⾯只有索引项的信息;
普通索引(⼆级索引):在InnoDB中,对于⾮主键,也就是其他字段,⽤户⾃⼰创建的索引,都叫做普通索引;假设以name列来创建⼀个索引,它的特征是:
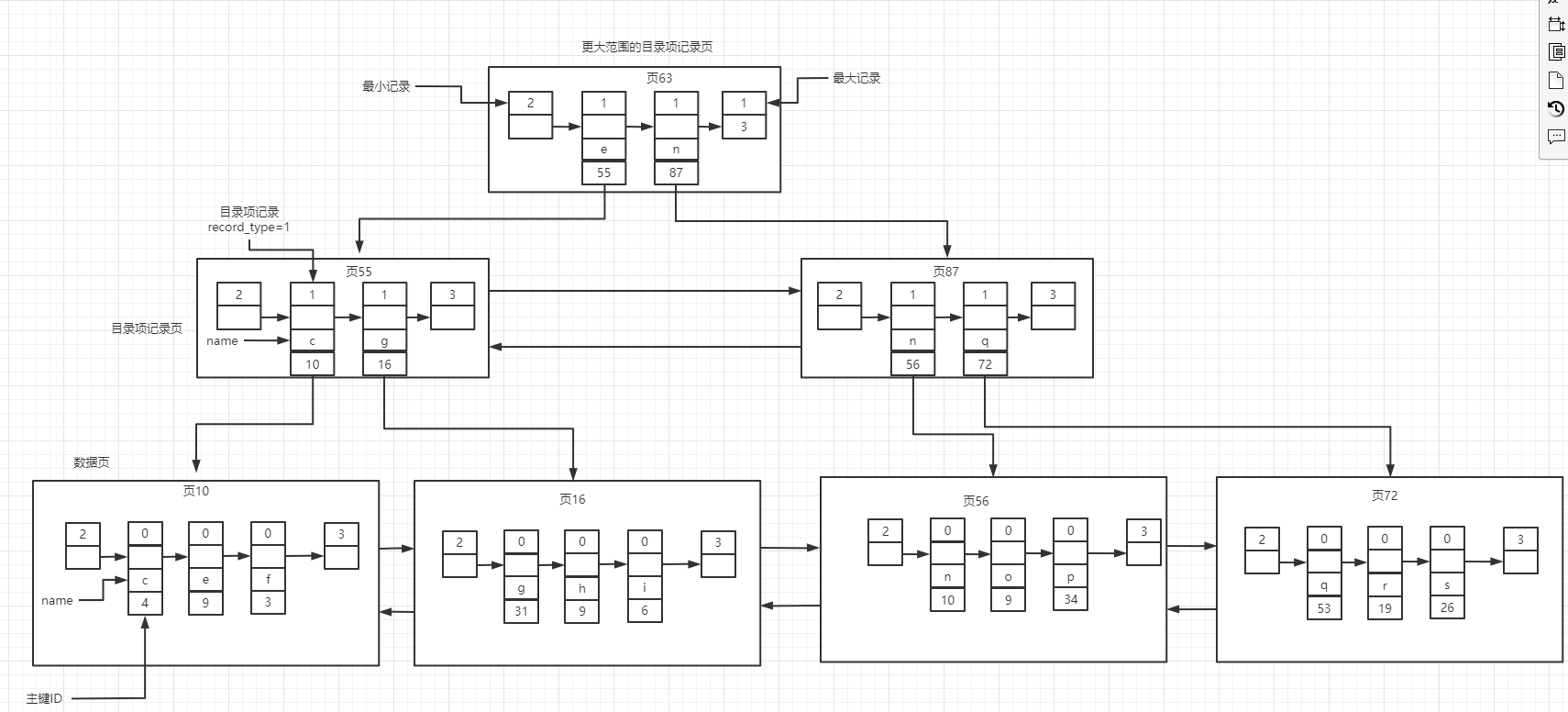
- 数据⻚中不再存储完整的数据⾏记录,⽽是name+主键两个字段的值,并且是按照name的顺序进⾏排序,将所有的数据⾏(name+主键)排列,组成⼀个单向链表;
- 索引树中的索引⻚(⽬录项记录⻚)中的⽬录项中存储的是name+⻚号(不再是主键ID+⻚号);并且索引⻚也是按照⻚中记录的最⼩name值排列,组成⼀个双向链表;
- 因为索引树的叶⼦节点(数据⻚)中没有所有的数据信息了,所以需要先⽤name找到对应的数据⾏,再根据这⾏数据⾥⾯的主键ID的值,再去主键索引中查找有完整数据信息的记录⾏(等于再⾛⼀遍主键索引的查询过程);
- 这个过程也叫做回表(回主键索引再去查⼀遍);这⾥的回表是⼀⾏⼀⾏地去搜索主键索引;
- 但是这⾥还有另外⼀个问题,⽬录项记录⻚中真的只有name+⻚号吗?
- 如果name的值为“abc”的记录⾏⾮常⾮常多,⽐如在数据⻚中存在了好⼏个数据⻚,那在上层的索引⻚中,不就会存在name相同⽽指向的数据⻚不同的⽬录项?
- 这个时候,那新插⼊⼀条name还是为“abc”的记录,会往哪个数据⻚插呢?那就没法判断了;
- 所以,对于⼆级索引的索引⻚中的⽬录项,会添加⼀个主键值,这样也就能保证其中的⽬录项除了⻚号这个字段外,是唯⼀的;
- 联合索引(也是普通索引):给多个列创建索引;假设以 name+age 列创建⼀个索引,特征是(这⾥只画图了索引⻚)
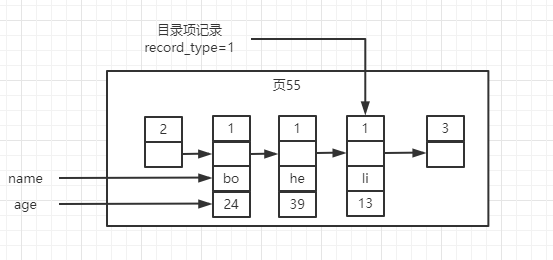
索引⻚中的记录⾏信息为:name+age,当然还有个指向数据⻚的指针漏掉了;
- 数据⻚中同样没有完整的记录⾏的所有数据信息,⽽是name+age+主键ID;
- 排序⽅式为:先按name排序,再按age排序;
- 所以联合索引同样也需要根据条件查找到记录⾏之后,需要回表到主键索引中查找有完整数据信息的记录⾏;
这⾥把普通索引说完了,那回到上⾯说到的⾮聚簇索引的知识点,普通索引是⾮聚簇索引吗?、
- 是⾮聚簇索引,因为普通索引存储索引信息的⽂件在普通索引这个索引树中,⽽存储它的具体的数据信息的⽂件在主键索引这个索引树中;
- 也就是说,存储索引信息和存储数据信息的⽂件是分开的,所以也属于⾮聚簇索引;
全局性地总结⼀下索引的理论知识
- 每个索引都对应了⼀棵B+树;对于⼀棵B+树,在性能较优情况下⼀般⽽⾔有3层:
- 上⾯两层是⾮叶⼦节点,对应的是索引⻚,⾥⾯只有索引项数据和指向下层⻚节点的指针;
- 最下⾯⼀层是叶⼦节点,对应的是数据⻚;
- 如果是主键索引,⾥⾯就存放了所有的⽤户记录的全部信息;
- 如果是普通索引,⾥⾯就存放了索引项内容和主键ID;
- InnoDB存储引擎默认会为主键ID创建⼀个聚簇索引(当你没有显示指定主键字段时,或者没有声明不能为NULL的unique字段时,InnoDB会⾃动添加索引,也就是数据⾏中的DB_ROW_ID那个隐藏字段);
- 然后对于其他需要的字段,我们可以单独创建普通索引;在使⽤普通索引进⾏查询时,需要执⾏回表操作,也就是在普通索引中找到了对应的记录⾏之后,还需要回到主键索引中去找到具有所有⽤户数据的记录⾏;
- B+树中每层的节点都按照索引列(主键ID、普通字段)的值从⼩到⼤顺序排列成了双向链表,并且每个节点⻚内部,也是按照索引列的值从⼩到⼤排列成了单向链表;因此索可以⽀持范围查询;
- 通过索引字段来查找数据时,是从B+树的根节点开始,⼀层⼀层地往下搜索的;先定位到记录在哪个数据⻚,然后在数据⻚中通过⼆分查找去找到对应的slot,最后再遍历slot中的单向链表,直到找到/找不到具体的记录⾏
2. 索引设计
2.1 回表
以⼀个SQL语句说明:
# money字段是有索引的
select * from user_account where money > 1000 and money < 100000; 对于user_account表,money字段创建了索引,也就是普通索引;
我们前⾯说过,对于普通索引,它的叶⼦节点只存储了索引项(mone)和主键id;
当你要查询⽤户记录的所有数据时,就需要使⽤主键id再到主键索引中查询所有数据信息,这也就是回表;
那么对于这个SQL语句,MySQL可以有两种查询⽅式:
- 1.直接以全表扫描的⽅式进⾏查询:
- a.也就是直接去扫描主键索引,因为主键索引的叶⼦节点中存储了所有数据信息,那就去对⽐整个表的所有数据⾏,判断搜索条件是否成⽴,如果成⽴就将这⾏记录加⼊结果集;
- b.但是主键索引是按照主键id的顺序来排列的,跟money字段没有顺序关系,所以需要从第⼀⾏⼀直扫描到最后⼀⾏为⽌;
- 2.使⽤money字段的索引进⾏查询:
- a.因为对money字段创建了索引,所以这个索引就会按照money的⼤⼩来进⾏排序;那这个时候就可以使⽤这个索引树来进⾏树搜索,查找到第⼀个money>1000的记录,然后遍历单向链表和双向链表直到money<100000的记录;
- b.但是money索引中,没有所有的数据信息,⽽我们的查询是select*,那就需要回表到主键索引中去查询;
- c.我们说过,InnoDB的索引是存储在磁盘中的,并且以数据⻚作为B+树的节点来组织的;那这些数据⻚就是在需要的时候,才从磁盘中加载到内存;
- d.假设查到了有50000条数据满⾜money>1000andmoney<100000,那对于其中的每⼀⾏数据,都要去执⾏⼀个回表操作(这⾥需要注意,是每⼀⾏都去做,⽽不能批量去做回表操作);
- e.也就是对于每⼀⾏数据,都有可能要去做⼀遍从磁盘中查找数据⻚并加载到内存中的操作,所以可想⽽知这个代价有多⼤;
那对于这个SQL语句,到底采⽤哪种⽅式来执⾏呢?
这就是我们前⾯讲到的查询优化器的⼯作:
- 它会去计算这两种⽅式各⾃需要消耗的成本,然后选择成本较⼩的⼀种⽅式来执⾏这个SQL语句;
2.2 索引的设计原则
覆盖索引:在使⽤普通索引进⾏查询时,数据⻚中只有索引字段+主键id,如果要查询其他字段就需要回表到主键索引中再次查询;
- 如果要查询的字段都在这个索引中,那也就不⽤再做回表操作了,这个时候也就叫做覆盖索引(也就是让查询列表中只包含索引列)
- 为了让最常⽤的where、orderby、groupby等语句都可以⽤到索引,就可以考虑覆盖索引;
最左匹配原则:对于联合索引,多个索引列 从最左边开始匹配,中间不能跳过或者有范围查询(模糊查询),否则会停⽌匹配(也就是不能使⽤到这个联合索引了);
- 为什么?
- 我们前⾯讲过,联合索引的组织⽅式为:先按key1进⾏排序,当key1相同时,再按key2进⾏排序,当key2相同时,再按key3进⾏排序;对于中间跳过的语句,如:wherekey1=’a’andkey3=’c’,当找到第⼀条满⾜key1=’a’的记录时,此时应该要去找key2相关的条件,但是这⾥直接没了key2,那在这个索引树中肯定就没法进⾏搜索了;
- 对于中间是范围查询的语句,如:wherekey1>’a’ and key2=’b’:key1是可以⽤到索引的,可以将所有key1>’a’的数据取出来;
- key2有序的前提是key1是确定的值,但是这⾥的key1是⼀个范围,也就是说key1可以是’b’、’c’、’d’……等等;
- 那在这个时候,对于key2就已经不是有序的了,也就没法使⽤树搜索了;
- 联合索引排序⽅式为:先按key1排序,key1相同时,再按key2排序;
- 但是当key1是范围时,这⾥就查出来了⼀堆key1,此时key2已经是⽆序的了,所以这种情况下没法⽤到索引;
- 另外,对于最左匹配原则,还有⼀个最左前缀匹配,也就是对于单字段索引,从字符的最左边开始匹配;
- 如:like’a%’;■like’%a%’或like’%a’不能⽤到索引
选择基数较⼤(区分度⾼)的列创建索引:对于⼀个字段,它的区分度越⼤则它的值不重复的⽐例就越⾼,此时扫描的⾏数就越少;
- 例如性别字段,⼀共就两个值,即使建⽴了索引,那它跟全表扫描也基本差别不⼤了;
选择字段类型较⼩的列创建索引:
- 在索引⻚中会存储字段的值,如果⼀个字段太⻓了,那就会占⽤很⼤的存储空间,则在⼀个索引⻚中能够存储的记录数就会变少,这样就会增加索引⻚数,也就增加了磁盘IO;所以尽量选择字段类型较⼩的列来创建索引;
- 如果要在较⼤的列上创建索引,则可以使⽤前缀索引:例如只对字段的前20个字符建⽴索引key(name(20));
索引列不能参与计算、嵌套函数、编码转换:因为索引是对于列的原值创建的B+树,如果你的查询条件中的值做了什么转换(计算、函数、编码等转换),那肯定就没法去到根据原值创建的B+树上进⾏树搜索了;
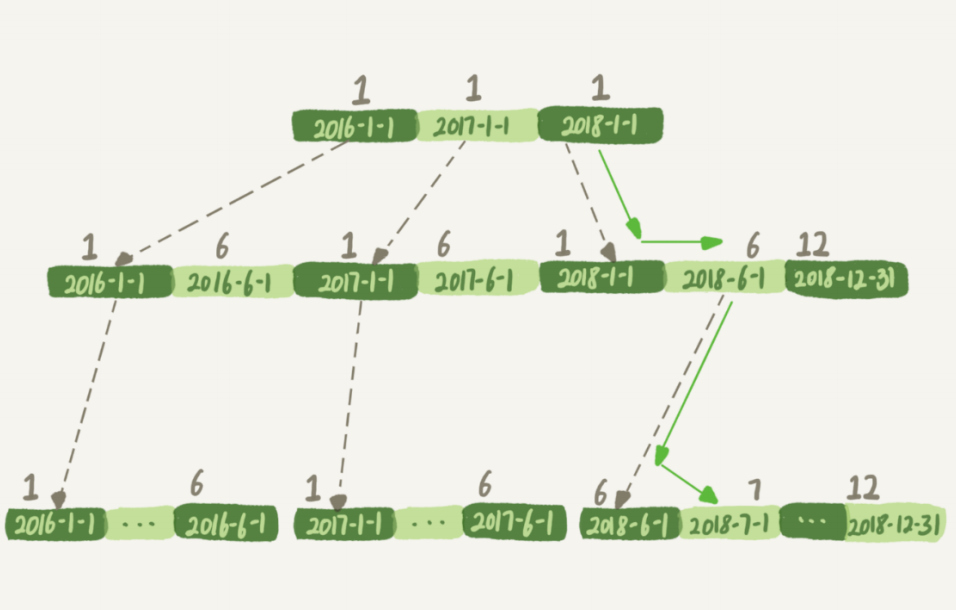
- 这个是对于t_modified字段创建的索引;
- 如果查询条件为where t_modified=’2018-7-1’,InnoDB就会按照绿⾊箭头的路线,快速定位到t_modified=’2018-7-1’的地⽅;
- 如果查询条件为wheremonth(t_modified)=7的话,则传⼊的值会是7,在索引树上第⼀层就搜索失效了;这个时候优化器会放弃⾛t_modified索引的树搜索;
- 这个是对于t_modified字段创建的索引;
尽量扩展索引,⽽不要新建索引:
- 由于每个索引都会创建⼀棵B+树,不仅会占⽤磁盘空间,在插⼊更新时还需要维护这颗树;
- 所以在需要新的索引字段时,先考虑是否可以在现有索引的基础上添加列来创建联合索引,⽽不是直接创建⼀个新的索引;
补充⼀个概念:索引下推(喵的每次面试都被问到):
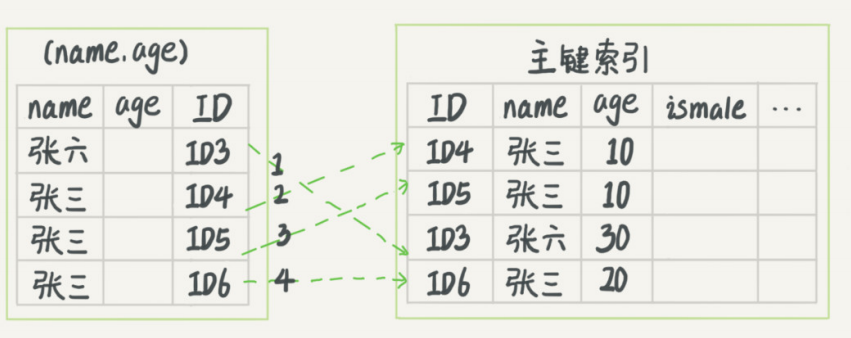
#这个 user表中有索引为 (name, age);
select * from user where name like '张%' and age=10我们前⾯介绍了最左匹配原则中的最左前缀规则,对于这种 张% 开头的可以⽤到索引的name字段;
但是因为它是模糊查询,对于联合索引(name,age)就没法搜索age字段了;
所以在使⽤了这个联合索引(name,age)查到满⾜条件的记录之后,还需要去筛选满⾜age条件的;这⾥的筛选⽅式就有两种了
每条都回表先获取到所有信息,然后在server层进⾏筛选;
也就是说从联合索引中取出的数据只判断name字段(不管age字段),满⾜name字段的就拿去回表了,获取所有的信息之后,再在server层进⾏筛选;
在MySQL5.6之前都是这样筛选的;
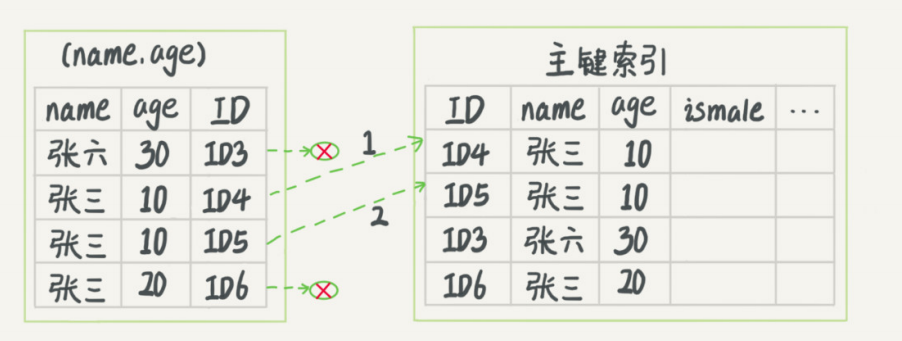
每条都先根据联合索引(name,age)中的age字段,先进⾏⼀次筛选(因为联合索引中是会记录age的值);
也就是将这个筛选的动作,下推到了存储引擎层实现,所以叫索引下推;
然后再将这些筛选过滤之后的满⾜条件的数据,进⾏回表;
显⽽易⻅,这种⽅式回表的记录数会⽐第⼀种少很多很多,所以是⼀种优化;
2.3 索引的设计案例
上⾯讲到了索引设计的时候要考虑到的多个原则,也就是理论性的东⻄,那我们接着使⽤⼀个案例来举例说明⼀下较为真实的场景下,怎么设计索引;(当然这⾥是单表情况下)
⾸先这⾥的场景是⼀个社交APP的场景:
- 表:user_info
- 字段:id,name,sex,age,weight,province,city,county,hobby,character,latest_login_time,score(评分)
下⾯根据各个不同的查询场景,来看看怎么去思考索引的设计:
场景⼀:
因为这是个社交APP,那肯定就要在上⾯搜索你感兴趣的⼈吧,那最简单的搜索条件为:
- 搜索年龄在20到30之间的,根据评分进⾏排序,并且限制结果⼈数为20⼈(也就是分⻚);
select * from user_info where age between '20' and '30' order by score limit xx, xx;- 在这种场景下,where条件中使⽤了范围查询,根据最左匹配原则,后⾯的排序和limit都没法⽤到索引了;
- 所以在这种情况下,你的where筛选和后⾯的orderby等没法都⽤上索引,就需要做⼀个抉择了:
- 你是要让where语句先基于索引去做⼀个筛选,筛选出来的部分数据,然后把数据加载到内存或者基于磁盘⽂件去进⾏指定条件的排序等,最后再分⻚;
- 还是说你是要让orderby按照你索引的顺序去找,然后找的过程中基于where语句来筛选出指定的数据,最后再分⻚;
- 这种情况下,⼀般都是使⽤where条件去快速地筛选出来⼀部分指定的数据,接着再进⾏排序和分⻚;因为根据你的where条件筛选之后的数据量,可能已经很⼩了,那么后续的排序和分⻚的成本就较⼩;
- 先满⾜where条件中的索引;
场景⼆:
你在搜索⽤户时,⼀般会加上省、市这三个地区字段得带上;性别字段应该也得带上
select * from user_info where province = 'xx' and city = 'xx' and sex = 'male' order by score limit xx, xx;- 对于这种情况,既然省市区基本是确定要带的,性别也基本是确定要带的;那我们肯定也就直接创建⼀个联合索引:joint_index(province,city,sex)
- 前⾯说过,基数较⼩的字段不要创建索引吗,为什么这⾥性别字段也创建索引了呢?
- 其实这⾥就是为了,在⽤到这个查询的时候,让你满⾜最左匹配原则,不然的话后⾯的字段就⽤不上了;
- 必选项字段,放在联合索引的最左侧;
场景三:
基于场景⼆和场景⼀,在搜索⽤户的时候,肯定还是会根据年龄进⾏筛选吧,所以往往会带上age字段;
select * from user_info where province = 'xx' and city = 'xx' and sex ='male' and age between '20' and '30' order by score limit xx, xx- 但是age字段⼜⼀般都是在⼀个范围内进⾏筛选,所以为了满⾜最左匹配原则,我们需要把age字段放在联合索引的最后⾯(最右边):joint_index(province,city,sex,age)
- 范围查询的字段,放在联合索引的最后;
场景四:
有些时候,对于有些⽤户还可能会按照⼀些个性化特征来搜索⽤户;例如:爱好(hobby)、性格(charactor)等,但是这些条件也有可能⼀部分⼈不会带上他们;那这个时候,如果把他们直接放到联合索引中
joint_index(province, city, sex, hobby, character, age)
不过,当未带上其中⼀个字段的话,那后续的字段也就⽤不上这个索引了;
设计技巧:可以发现,这些字段其实都是有⼀些固定的枚举值的,例如:
- hobby:运动、电影、看书、旅游等;
- character:温柔、内向、外向、体贴等;
基于这个特性,那上⾯的问题就可以在SQL语句中进⾏解决了:
where province = 'xx' and ... and hobby in ('xx', 'xx', 'xx') and character in ('xx', 'xx', 'xx') and age between ...;
当⽤户未带上这个字段时,就直接使⽤⼀个装有所有的枚举值的list进⾏查询;
当⽤户带上了这个字段时,就把这个所有值的list,替换成⽤户传递的list;
这样的话,就可以让这两个字段也包含在索引中,⽽且肯定都能⽤上;
含有枚举值的可选字段,使⽤in来让它们保证能⽤上索引;
场景五:
大部分搜索⽬标⽤户的场景,肯定都想要得到的结果是活跃⽤户吧,那些⼀两个⽉都没有上线过的⽤户,搜索出来也没有意思;
- 所以⼤部分的搜索会带上⼀个例如最近7天在线的条件;
- 在我们的表中,有⼀个字段latest_login_time,表示的是最后的登录时间;如果想要使⽤这个字段的话,那就需要对它进⾏⼀些函数处理或者范围查询;
- 但是这样的话也会导致⽤不到索引,或者导致后⾯的字段⽤不到索引(因为已经有了⼀个age的范围查询了);
- 设计技巧:在表中增加⼀个字段is_login_in_latest_7_days,每天定时去维护这个字段;
- 那此时,就可以把这个字段加⼊到联合索引中了:
- joint_index(province,city,sex,hobby,character,is_login_in_latest_7_days,age)
- 对⼀些字段,做特殊处理(增加字段)来可以⽤上索引;
场景六:
可能会存在⼀些⽤户,他不按常理出牌,⽐如他就设置⼀个搜索条件,其他什么条件都不带;例如就设置sex为⼥性,则SQL为:
where sex = 'female' order by score limit 0, 20;如果还是⽤上⾯的那个联合索引,那sex是中间字段,肯定没法⽣效的;⽽且基数还很⼤,最后取出来⼏百万条数据,还要去磁盘中排序再分⻚什么的,这样效率会⾮常差的;
所以对于这种⼩众的条件假设排序的搜索,可以单独创建⼀个索引:idx_sex_score(sex,score);对⼩众搜索条件,单独创建索引;
设计核⼼:
- 尽量⽤⼀两个复杂的多字段联合索引,来覆盖到80%以上的查询;
- 再⽤⼀两个⼩众的辅助索引,来覆盖剩余的15%左右的查询;
- 也就是说,基本能保证95%以上的查询都能充分利⽤索引,就能保证你的查询性能了;

