MySQL ⽇志(Redolog Undolog Binlog)
1. Redolog
在前⾯我们对Redolog下过⼀个定义:它是崩溃⽇志,⽤来⽀持崩溃恢复的;为什么需要它呢?
- 因为MySQL为了提⾼⾃⼰的性能,避免⼤量的磁盘随机IO的发⽣,将原本应该发⽣在磁盘数据⻚ 中的更新操作放在了内存bufferpool的缓存⻚中;
- 这个更新是在内存中,如果此时MySQL服务挂掉,或者说Linux服务器宕机了,那在内存中的数据肯定就会丢失了;
- 所以,在写⼊内存buffer pool 之后,需要将更新的内容进⾏⼀个落盘(也就是写到磁盘);那这⾥也就是写⼊到Redolog⽇志⽂件中了;
前⾯也说过,写⼊Redolog⽇志⽂件也是⼀次写磁盘,直接写数据⻚也是⼀次写磁盘,为什么要这样实现呢?
- 因为直接写数据⻚,会是随机IO,要更新的数据在磁盘上是随机分布的;
- ⽽写Redolog则是顺序IO,挨着挨着写进去就⾏了;
- 并且Redolog占⽤的空间更⼩,因为它只存储了更新的内容;⽽数据⻚是存储了所有数据信息;
然后有定时的IO线程,或者bufferpool满了,会对bufferpool中的脏⻚进⾏刷脏,即把更新应⽤到具体的磁盘数据⻚上;
在还有未刷脏的缓存⻚时,如果发⽣了宕机,内存中的数据丢失;重启之后,就需要从Redolog中进⾏数据恢复了;
也就是说,Redolog就是记录⼀下你在内存中修改了哪些东⻄,然后如果服务崩溃的时候⽤来进⾏数据恢复;
1.1 Redolog 相关配置
Redolog⽂件路径:
- 在前⾯讲过,可以在/etc/my.cnf->/var/lib/mysql⽬录中看到两个⽇志⽂件:ib_logfile0、ib_logfile1;
- 也可以直接查看MySQL的参数innodb_log_group_home_dir,找到具体的⽬录地址;
Redolog⽂件⼤⼩:innodb_log_file_size,默认48M;
Redolog⽂件数量:innodb_log_file_in_group,默认2个;
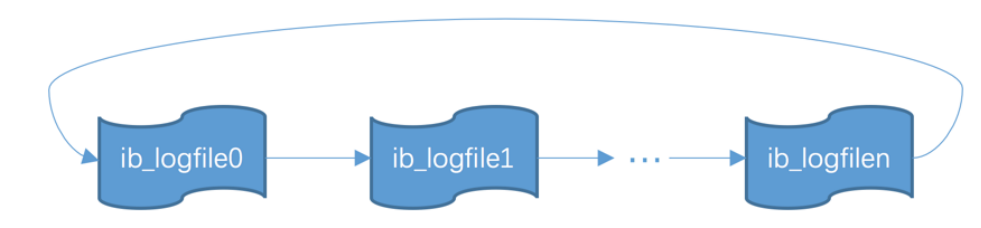
磁盘中的Redolog⽇志⽂件不是只有⼀个的,⽽是以⼀个⽇志⽂件组的形式存在的;它的命名是根据上⾯的⽂件数量,从0到N;
在写⼊Redolog时,是先从ib_logfile0开始写,当ib_logfile0写满了,就接着ib_logfile1写,然后接着往ib_logfileN写;
当都写满的时候,就会回过头去,再次去写ib_logfile0,也就是⼀个循环写⼊的过程。
Redolog提交策略:innodb_flush_log_at_trx_commit:
- 0:每次提交事务,数据只留在redologbuffer中,不刷⼊磁盘;
- 1:每次提交事务,都会将redologbuffer中的数据刷⼊到磁盘;
- 2:每次提交事务,都会将redologbuffer中的数据刷⼊oscache,但是没有flush到磁盘;
1.2 Redolog⽇志格式

- type:表示这条Redolog的类型;根据在数据⻚中写⼊了多少字节的内容,划分为了以下⼏种Redolog⽇志类型:
- MLOG_1BYTE:表示在⻚⾯的某个偏移量处写⼊1个字节;(type值为1)
- MLOG_2BYTE:表示在⻚⾯的某个偏移量处写⼊2个字节;(type值为2)
- MLOG_4BYTE:表示在⻚⾯的某个偏移量处写⼊4个字节;(type值为4)
- MLOG_8BYTE:表示在⻚⾯的某个偏移量处写⼊8个字节;(type值为8)
- MLOG_WRITE_STRING:表示在⻚⾯的某个偏移量处写⼊⼀串数据;(type值为30)
- 还有⼀些其他的复杂的类型,我觉得我们也没有必要去掌握那么细了
- spaceID:表空间ID,表示这条Redolog对应的SQL语句是在哪个表中执⾏的,对应的表空间ID是多少;
- pagenumber:数据⻚号,表示这条Redolog对应的SQL语句更新的是哪个数据⻚中的内容;
- data:
- 偏移量:表示在数据⻚中的什么位置,开始执⾏更新的;
- ⻓度:表示修改了多少⻓度的数据;
- 数据:表示具体修改了那些数据;
根据data的内容,我们可以看出来,Redolog记录的是对于⼀个具体的数据⻚,在什么位置执⾏的修改、修改了多少⻓度的数据、具体修改了什么内容;
因此Redolog是⼀个物理⽇志,也就是记录了物理层⾯的修改;
1.3 Redolog写⼊过程
1.3.1 redo log block
我们知道对于bufferpool,它划分为了多个数据⻚,以数据⻚为单位来装载多条数据⾏;
类似的,对于Redolog⽇志,也不是直接⼀⾏⼀⾏的写⼊的;⽽是也设计了⼀个叫redologblock的东⻄,以它为单位,来存放多⾏Redolog⽇志;
⼀个redo log block占⽤512字节,格式为:
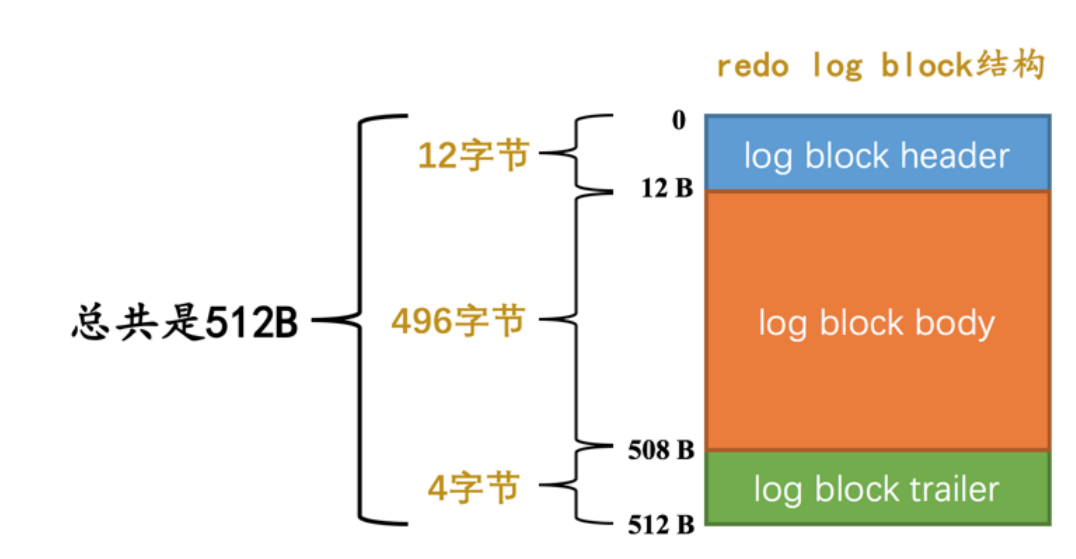
log block header和log block tailer都是存放⼀些管理信息;
真正的Redolog⽇志,是存放到log block body中的;
1.3.2 redo log buffer
前⾯也提过,为了避免直接写⼊ 磁盘中的Redolog⽇志太慢,InnoDB也设计了 redo log buffer 这样⼀块
内存缓冲区;
⼤⼩由innodb_log_buffer_size参数控制,默认为16M;结构如下
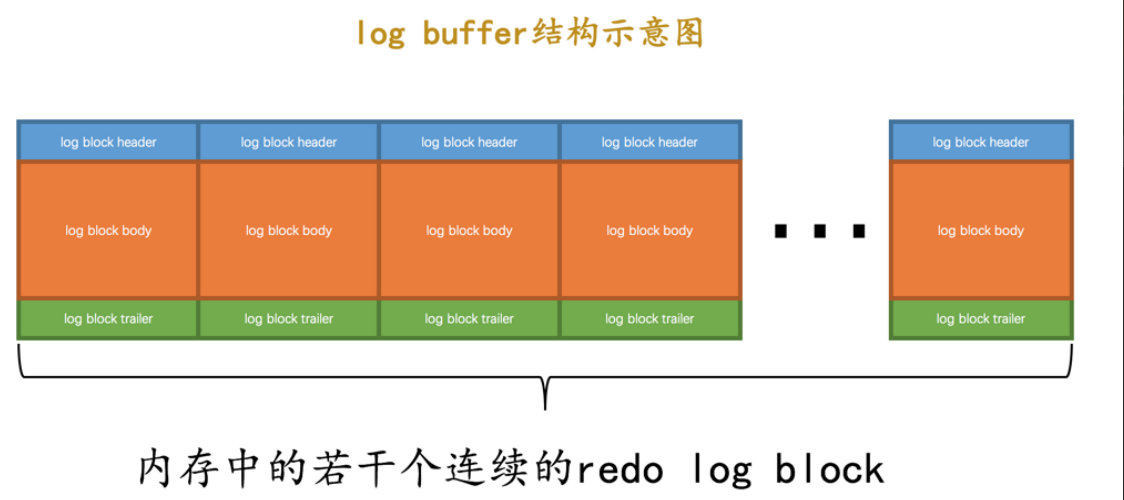
其实跟磁盘中的 数据⻚ <-> buffer pool 中的缓存⻚对应关系类似,这⾥也是redo log buffer中的 block <-> Redolog⽇志中的 block;
1.3.3 Redolog 执⾏流程
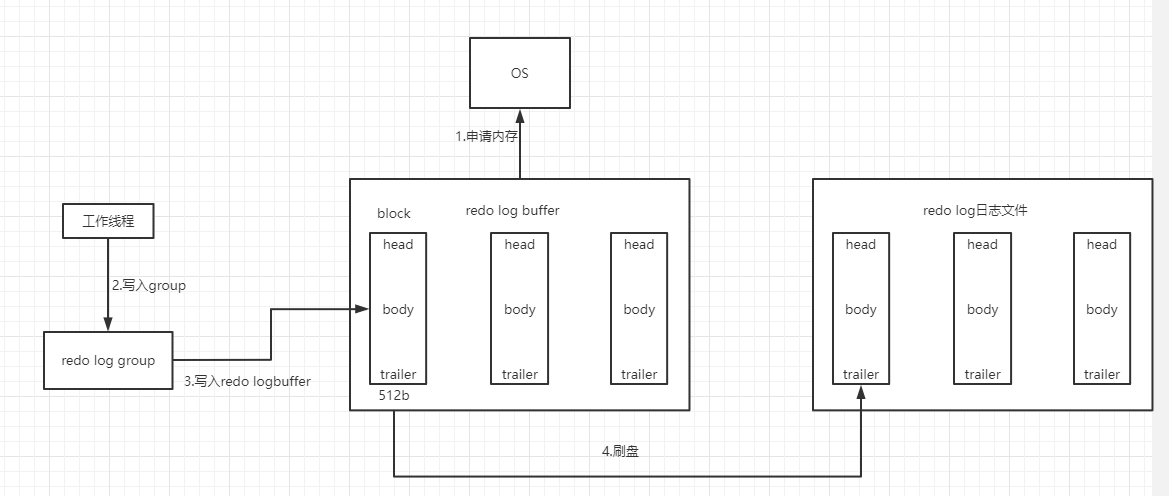
- 1.在MySQL启动时,向操作系统申请一块连续的内存空间redo log buffer,并且在redo log buffer中按照512字节的大小划分出N个空闲的redo log block;
- 2.工作线程执行时开始写redo log日志,但是一个事务可能会有多个操作,那么就会有多个redo log记录,这个redo log就是一组redo log group,这组redo log会在其它地方暂存;
- 3.等事务执行完(非提交)之后,才会把这组redo log 先写到redolog buffer中的一个空闲的block中,由于一个block只有512个字节,所以一组redo log可能会写入到多个block中
- 4.将redo log buffer中的block刷入redo log日志文件中,
- 磁盘的redo log文件也是以block的方式存储
- 刷盘时机:
- 1.redo log buffer中的日志大小已超过了总容量的一半(8MB),此时会刷入磁盘文件
- 2.一个事务在提交时,根据他的提交策略,把与这个事务相关的block刷入磁盘(即innodb_flush_log_at_trx_commit=1时,每次事务提交都会刷入redo log日志,从而保证数据绝不丢失)
- 3.后台线程每隔1s会将redo log buffer中的block刷入磁盘(未提交事务的redo log也有可能刷入磁盘)
- 4.MySQL关闭时,redo log buffer 中的block都会刷入磁盘。
1.4 checkpoint
这⾥再提⼀下Redolog的checkpoint过程;
Redolog的作⽤是在系统崩溃恢复的时候⽤来恢复脏⻚中的数据的;那如果对应的脏⻚已经刷新到了磁盘中,此时即使服务宕机也不会有任何影响;
那这些已经刷脏了的磁盘对应的Redolog⽇志也就没有存在的必要了,即它所占⽤的内存空间是可以被重⽤的了;
因此,每次刷脏完成,则对应的Redolog可以被覆盖掉了,就会做⼀次checkpoint操作,这个checkpoint的作⽤就是去检查和记录哪些Redolog可以被覆盖;
崩溃恢复的过程:
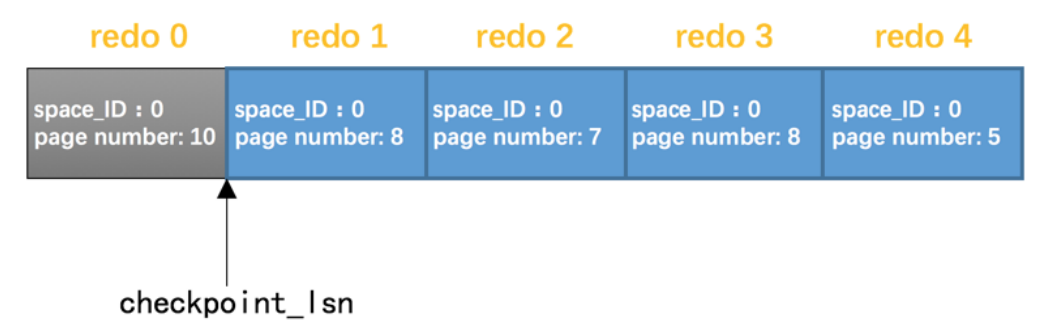
这⾥的checkpoint_lsn就是前⾯的checkpoint做的标记,表示已经刷脏了的Redolog操作,也就没有必要再去恢复了;
所以就从checkpoint_lsn后⾯的Redolog 开始读取,然后顺序扫描每条⽇志,按照⽇志中记录的内容将对应的⻚⾯恢复出来即可;
2. Undolog
Undolog
- 1.它是回滚⽇志,⽤来⽀持事务的回滚操作;
- 2.另外,它也⽤来实现事务的MVCC;
回滚:
- 即事务执⾏的过程中修改了很多东⻄,但是执⾏到某个地⽅突然抛出了错误,或者你⼿动执⾏了回滚操作,此时就需要将修改的东⻄还原成原来的样⼦;
要实现将修改的东⻄给还原回去,那就得有⼀个地⽅,将这些修改的东⻄给记录下来;例如:
- 插⼊了⼀条数据,那得把这条数据的主键id记录下来,在回滚的时候根据这个主键id把数据给删掉;
- 删除了⼀条数据,那得把这条数据的全部内容记录下来,在回滚的时候把这些内容⼜重新插⼊回去;
- 修改了⼀条数据,那得把这条数据的修改前的旧值记录下来,在回滚的时候把旧值去重新更新回去;
2.1 Undolog 表空间
InnoDB采⽤表空间+回滚段的⽅式来存储Undolog,这个回滚段定义了Undolog的组织⽅式;
在具体实现中,可以将Undolog与InnoDB的数据⽂件(也就是那个ibdata1)存储在⼀起,也可以将Undolog单独存储,这个取决于MYSQLinitialize时的参数配置;我们下⾯都以独⽴的Undo⽂件来介绍;
- UNDO TABLE SPACE
- Undolog的表空间,每个表空间都对应⼀个独⽴的物理⽂件(也就是UndoX);UndoX⽂件的数量由参数undo_tablespaces控制,默认值为8
- UNDO ROLL BACK SEGMENT
- 使⽤独⽴表空间存储的Undolog,会为每个undotablespace创建⼀定数量回滚段,由参数srv_rollback_segments控制,默认值为128;将TABLESPACE划分为SEGMENT的⽬的是可以让每个事务⼯作在不同的SEGMENT上⽽不会互相⼲扰,以此提⾼并发度
使⽤独⽴表空间组织形式的UNDO TABLE SPACE的组织可以⽤下图来表示:
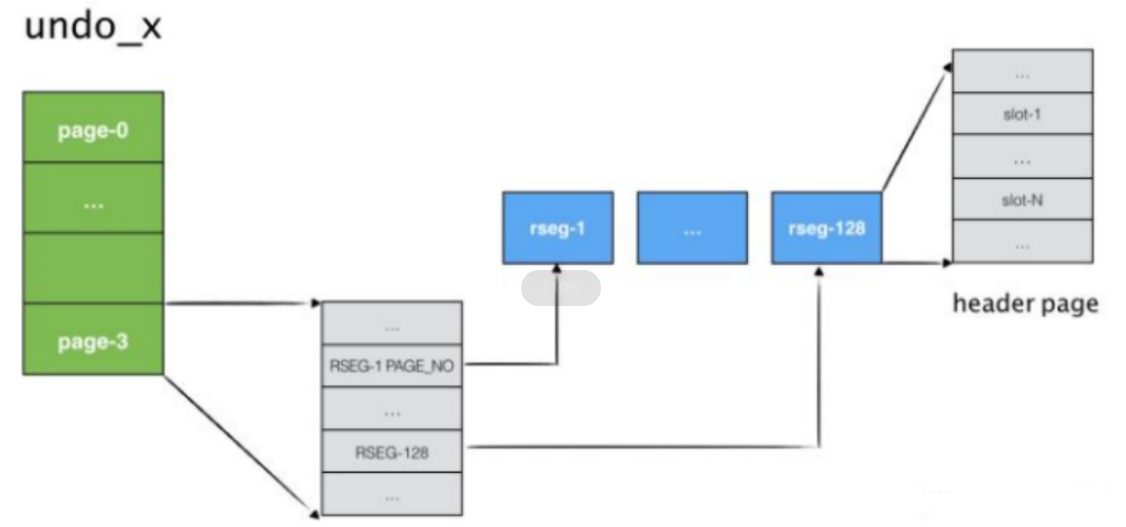
- 表空间的第4个page(page-3)内主要存储该表空间内的每个回滚段的headerpageno,构成⼀个数组,数组⼤⼩为回滚段数量,数组的每⼀项占据4B;
- 回滚段的header page内有undo log slot数组,如果page⼤⼩为16KB,那么该数组⼤⼩为1024,数组的每⼀项代表⼀个undo log,事务运⾏需要记录undolog时会寻找当前空闲slot分配undolog;
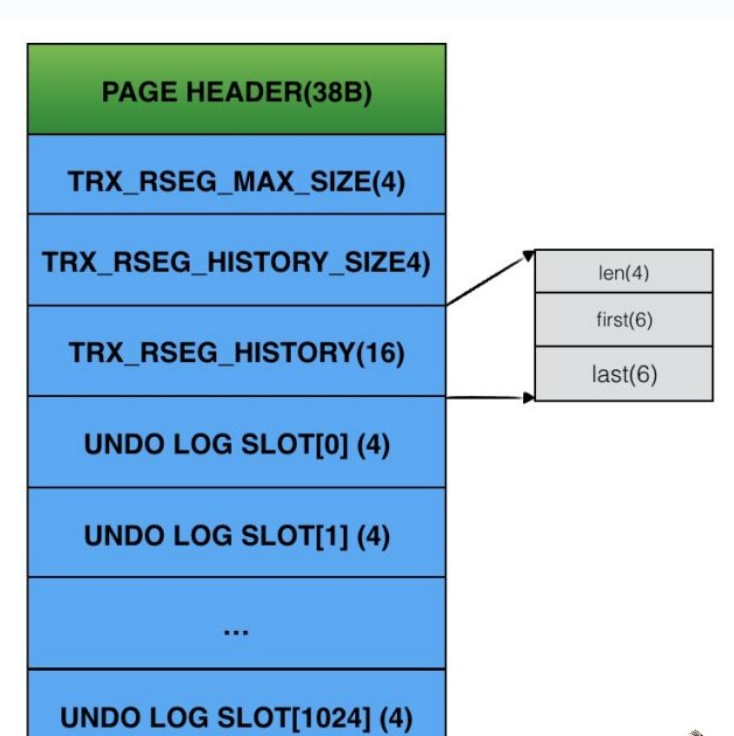
- 即⼀个page中有 1024个undo log;
另外,临时表空间也存在⾃⼰的回滚段,临时表空间在每次系统启动时都会创建;因此,临时表空间的信息⽆需持久化,所以创建临时表空间时⽆需记录Redolog;
UndoLog⽣成流程:
每个事务开启的时候,就会创建⼀个trx_undo_t对象,此时会从UndoX的page上先去分配⼀个UndoSegment,以后这个事务上所有的Undolog所需的page都从这个Segment上分配;
这个Segment的第⼀个page被称为headerpage,其他的page都是普通page;
对于headerpage:trx_undo_state:它相对于普通page多了⼀些属性,⽤来记录事务的状态:active/prepared等;
trx_undo_last_log:最后⼀个Undolog在undopage中的地址,可⽤来快速地定位到最新的Undolog;
trx_undo_page_list:这个segment中所有page组成的双向链表的头部,可⽤来遍历所有page的Undolog;对于普通page:
每个undopage只会存储⼀种类型的undolog;
也通过trx_undo_page_node来构成双向链表;
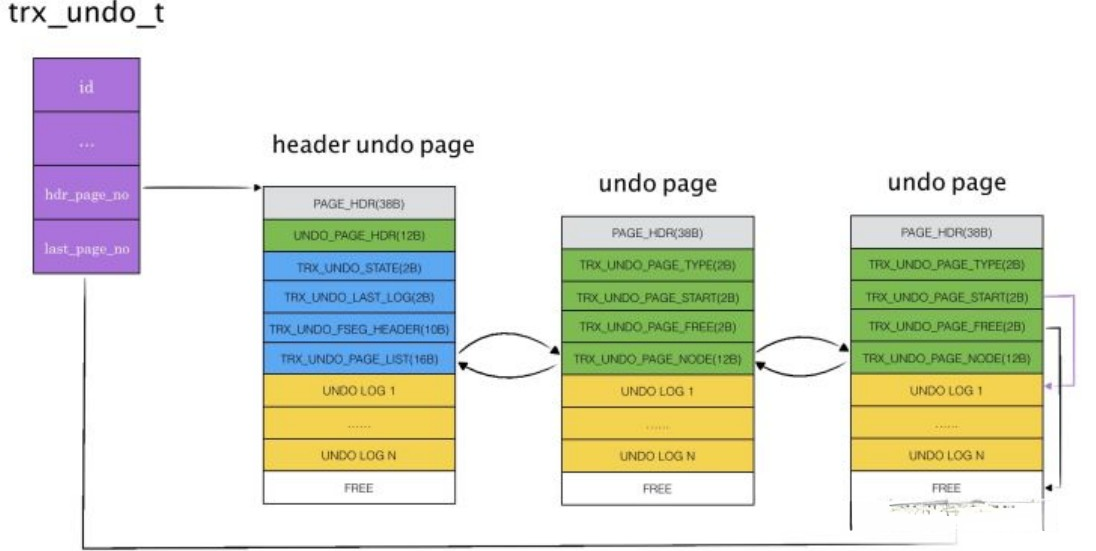
注意这⾥是针对的⼀个事务创建的 trx_undo_t对象,因为⼀个事务中可能包含多个语句,⽽且⼀个语句中可能会对多条记录进⾏改动;
对于每条记录在改动时,都会记录⼀条Undolog,所以在⼀个事务执⾏过程中可能会产⽣很多Undolog,可能⼀个⻚⾯还放不下;
因此,这些Undolog会被放在多个⻚⾯,并且连接成链表形式;
并且这⾥的同⼀个undopage只会存储⼀直类型的Undolog,例如⼀个undopage只存储TRX_UNDO_INSERT的Undolog,⼀个undopage只存储TRX_UNDO_UPDATE的Undolog;
2.2 Undolog ⽇志格式
InnoDB中有两个Undolog⽇志:
- ⼀个是由更新/删除产⽣的Undo log :insert undo record

- 头部和尾部分别表现这个Undolog的开始地址和结束地址;
- TRX_UNDO_INSERT_REC:Undolog的⽇志类型;
- undo_no:Undolog编号;
- Tableid:Undolog对应的记录所在表的tableid;
- Unique_field_len/value:主键或者唯⼀索引,占⽤的存储空间,和真实数据;
- 另⼀个是由更新产⽣的Undo log :update undo record
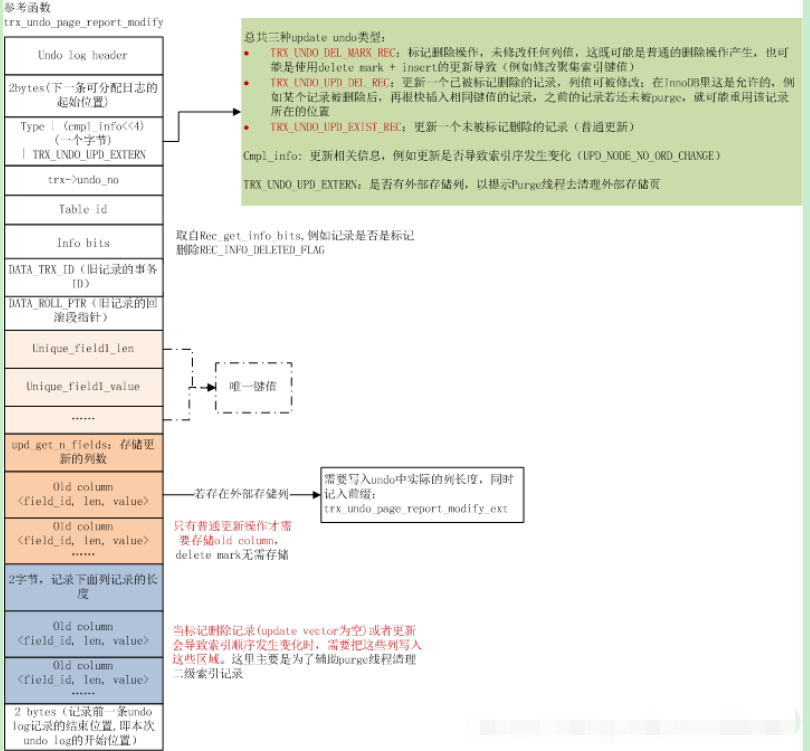
- 公共部分都前⾯的⼀样insert类型⼀样;
- 只是这⾥的类型分为了三种:直接删除、更新未删除、更新已删除;
- 这⾥也有主键或者唯⼀索引,占⽤的存储空间,和真实数据;
- 除了上⾯这些之外,因为是更新,所以还需要记录:
- 有多少列被更新了;
- 这些列更新前是什么值;
- 但是这⾥有两个重点:
- data_trx_id:旧记录的事务Id,即上⼀次修改这个记录的事务id;⽤于实现MVCC中的可⻅性⽐较;
- data_roll_ptr:旧记录的回滚段指针,即指向这条记录的上⼀次修改的Undolog;⽤于实现Undolog版本链;
- 这个Undolog版本链,是⼀个⾮常重要的东⻄,这⾥先提⼀下:
- 这是对于同⼀个记录的多次操作,每次操作都会对应⼀条Undolog;
- 并且每条Undolog,都通过data_roll_ptr来指向这条记录上次被修改对应的Undolog;
- 这样就形成了Undolog版本链了;
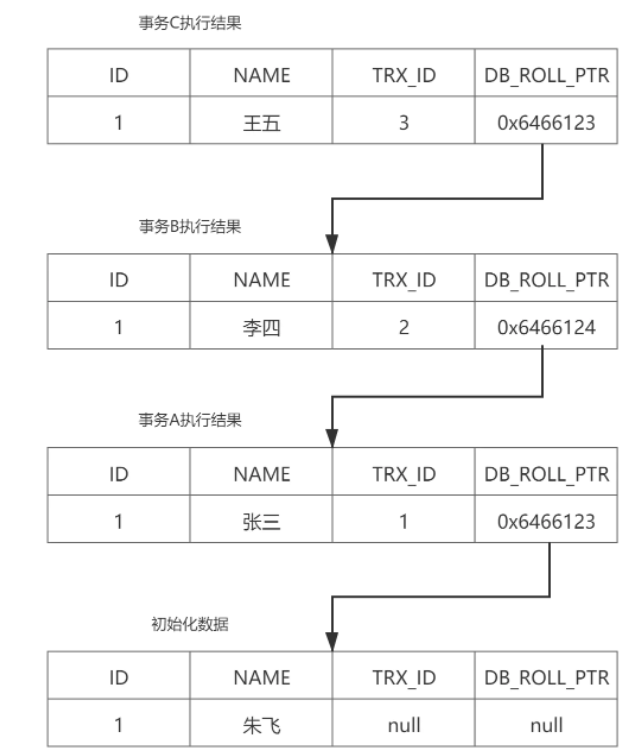
可以看到,insert的Undolog要简单很多,因为它记录的是插⼊的数据,如果你对于插⼊的数据要回滚,那直接⽤id来删除了即可;
但是对于更新这些操作,如果要回滚,就需要使⽤到更新以前的数据,所以也需要记录这些数据;
Undolog它记录的是对于某些字段更新前是什么内容,是由谁去更新的,⽽不是记录的是在磁盘物理地址上真正更新的内容;
所以Undolog是逻辑⽇志;
3. Binlog
说到Binlog,我们先来说下它最主要的使⽤场景,
- MySQL主从复制:即在master端开启binlog,master在⽣成binlog之后,传递到slaves来达到主从数据⼀致;
- 数据恢复:在你删除或者执⾏了⼀些误操作之后,你想要恢复到原来的样⼦,也就需要依赖binlog来进⾏数据恢复;(⼀般是使⽤mysqlbinlog⼯具,或者⼀些第三⽅的开源⼯具操作)
先来看⼀下两个概念:
- DDL:Data Definition Language,数据库定义语⾔,对数据库中表结构进⾏操作的语句;如create、alter、drop等;
- DML:Data Manipulation Language,数据操纵语⾔,对数据库中的数据进⾏操作的语句;如select、update、insert、delete等;
binlog⾥⾯记录的内容有:
- 所有的DDL操作,
- 及除了select之外的DML操作;
3.1 binlog ⽇志格式
binlog是以事件形式来记录对MySQL数据库执⾏的所有更新操作的;它从⼀个binlog⽂件头开始,然后是⼀堆binlog事件:
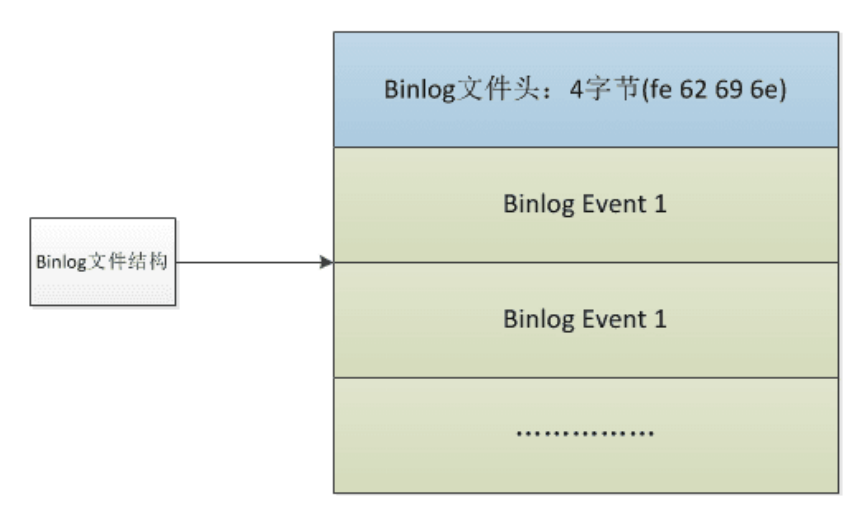
这个⽂件头其实就是⼀个四字节的魔数(MagicNumber),在内存中是”0xfe0x620x690x6e”;这个就是⽤来验证这个binlog⽂件是否有效;
- 在Java的class⽂件中,也有这样⼀个四字节的魔数:0xCAFEBABE;
事件 Event
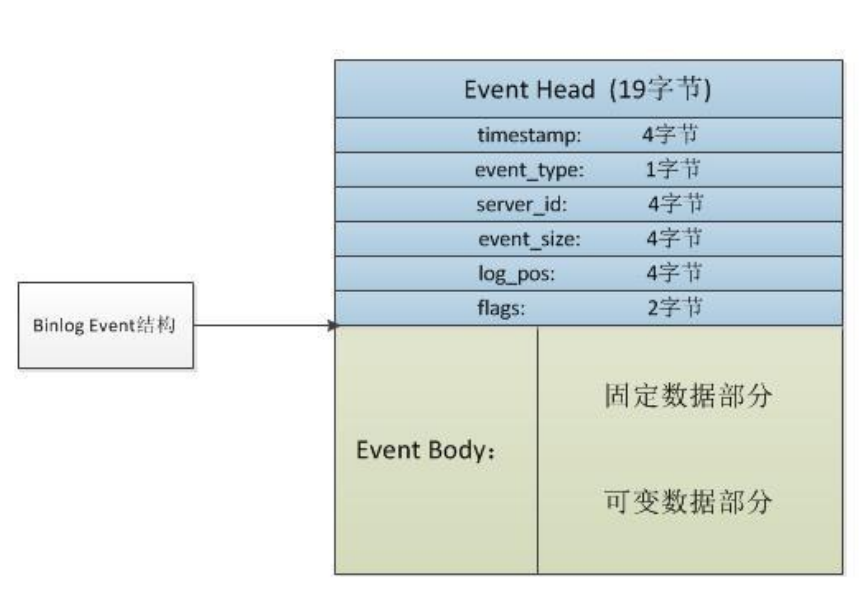
- 每个binlog事件,都以⼀个19字节的事件头(EventHeader)开始,然后是⼀个binlog事件类型特定的数据部分,即事件体(EventBody);
- BinlogEvent的结构与具体的事件类型有关,它的常⻅事件类型有:
- FORMAT_DESCRIPTION_EVENT
- PREVIOUS_GTIDS_EVENT
- TABLE_MAP_EVENT
- WRITE_ROW_EVENT
- DELETE_ROW_EVENT
- UPDATE_ROW_EVENT
- XID_EVENT
- FORMAT_DESCRIPTION_EVENT
- ROTATE_EVENT
最终⼀个binlog的格式⼤概为:
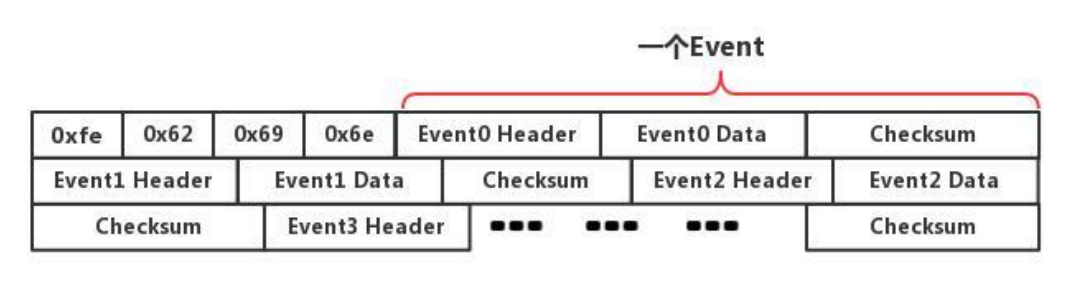
3.2 binlog 三种格式
binlog有三种格式,分别是:
- statement
- row
- mixed(也就是两种格式的混合);
为了说明这⼏种格式的区别,我们创建⼀个表:
mysql> CREATE TABLE `t` (
`id` int(11) NOT NULL,
`a` int(11) DEFAULT NULL,
`t_modified` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
KEY `a` (`a`),
KEY `t_modified`(`t_modified`) ) ENGINE=InnoDB;
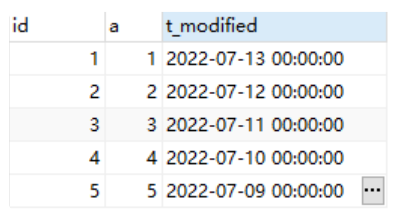
insert into t values(1,1,'2022-07-13');
insert into t values(2,2,'2022-07-12');
insert into t values(3,3,'2022-07-11');
insert into t values(4,4,'2022-07-10');
insert into t values(5,5,'2022-07-09'); 插⼊后表中数据为:
我们来执⾏⼀条删除语句,看看binlog是怎么记录的;
3.2.1 statement
⾸先先切换成 statement 格式:set binlog_format=STATEMENT; ,这⾥的话可能有些版本需要去改配置⽂件才⾏:
binlog-format="STATEMENT"
// 之后可⽤这个语句查看:
show variables like '%binlog_format%';再来执行删除操作
mysql> delete from t where a>=4 and t_modified<='2022-07-10' limit 1;
- 第⼀⾏SET@@SESSION.GTID_NEXT=’ANONYMOUS’可以先忽略,是⽤来实现主备切换的;
- 第⼆⾏begin:表示开启⼀个事务,跟最后的commit对应;
- 第三⾏就是真实执⾏的命令了;可以看到,在真实执⾏的delete命令之前,有⼀个usetest命令,也就是使⽤test这个数据库(跟我们使⽤mysql客户端命令⼀样,需要先指定⼀个数据库);
- 这是MySQL根据当前要操作的表⾃动添加的,这样可以保证到从库中去执⾏的时候,能够正确地应⽤到test库的t表;
- 后⾯的delete语句,就是我们输⼊的SQL语句了;可以看到statement格式的binlog记录了真实的原⽂;
- 最后⼀⾏也就是commit;⾥⾯还有⼀个xid=22,这个是Redolog和Binlog共同的字段,我们前⾯讲到过它们有⼀个两阶段提交,就是使⽤这个xid来作为两个⽇志中的公共数据字段,便于查找;
下⾯再来执⾏⼀条语句:
show warning;
可以看到,上⾯的那条delete命令产⽣了⼀个warning;为什么会产⽣这个warning呢?
因为上⾯的statement格式记录的binlog,可能会导致主备不⼀致,也就是说这个命令是Unsafe的;那来看看是怎么导致主备不⼀致的:
- 因为这条delete命令使⽤的是索引a,也就是会根据索引a找到第⼀个满⾜条件的⾏,也就是说删除的是a=4这⼀⾏;
- 但是如果在从库中,使⽤的是索引t_modified的话,那找到的第⼀个满⾜条件的⾏,就会是t_modified=’2022-07-09’,也就是a=5这⼀⾏了;
- 也就是说,binlog在statement格式下,记录的是SQL语句的原⽂;但是这样的话,就可能出现在主库执⾏的时候使⽤的是索引a,但是在从库去执⾏的时候使⽤的是另外⼀个索引,然后导致删除的数据不对;这样是有⻛险的,所以MySQL也给出了⼀个warning;
3.2.2 row
再来看看row格式 的binlog是怎么记录的;也是先把 binlog的format改成row:
binlog-format="ROW"
// 之后可⽤这个语句查看:
show variables like '%binlog_format%';重新把那条记录插⼊到表t中,执⾏删除语句:
mysql> delete from t where a>=4 and t_modified<='2022-07-10' limit 1;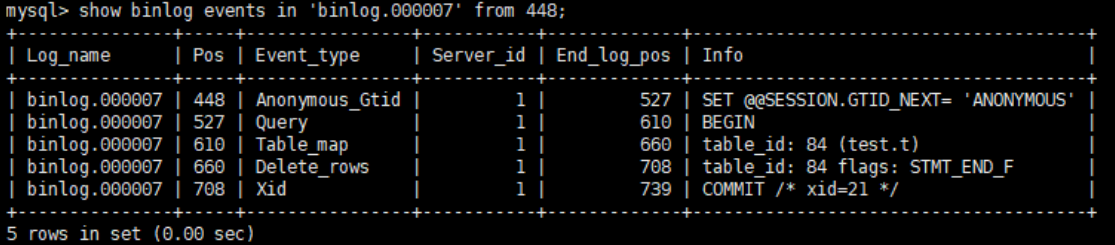
- 可以看到,第⼀⾏SET,第⼆⾏begin,第三⾏commit,都跟statement格式的⽇志是⼀样的;
- 从第三⾏开始,row格式的binlog中没有了SQL语句的原⽂,⽽是替换成了两个event:
- Table_map:说明接下来要操作的表是test.t;Delete_rows:⽤于定义是删除⾏操作;
这⾥⾯啥都看不到,因为row格式的binlog⽇志就只记录了这些,我们需要使⽤mysqlbinlog这个⼯具来解析binlog中的内容;上⾯图中的开始Pos位置是448,所以我们就从448处开始解析:
/usr/bin/mysqlbinlog -vv /var/lib/mysql/binlog.000007 --start-position=448
# 注意这个不是在 mysql客户端执⾏,⽽是在外⾯命令⾏执⾏的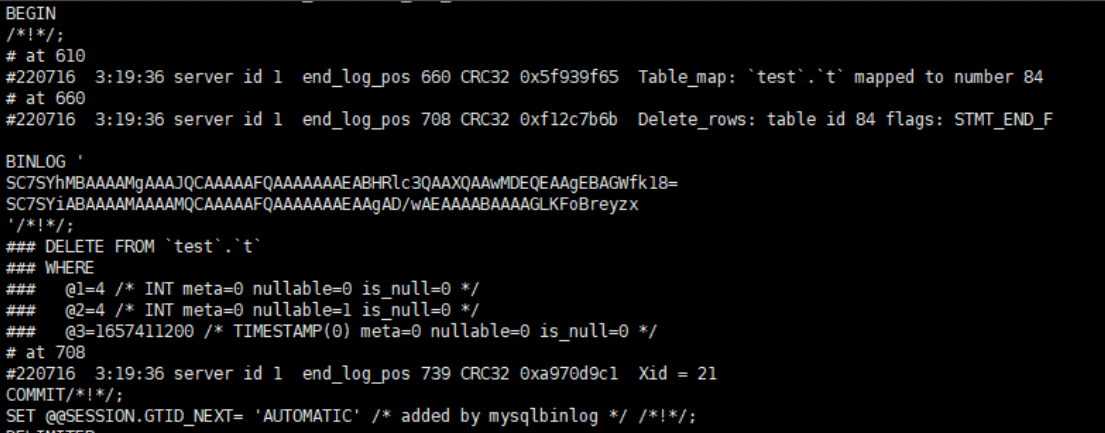
server id 1:表示这个事务是在server_id=1的这个库上执⾏的;
CRC320x5f939f65:每个event都有CRC32的值,⽤来做校验;
Table_map:跟上⾯的⼀样,说明接下来要操作的表是test.t;map到数字84;
- 这⾥是单表操作,如果是多表操作,那每个表都会有⼀个对应的Table_mapevent,分别会map到⼀个单独的数字;
前⾯的mysqlbinlog命令中使⽤了-vv参数是为了把内容都解析出来;所以这⾥结果中可以看到各个字段的值:
- @1=4,第⼀列值为4(id);
- @2=4,第⼆列值为4(a);
- @3=1657411200,第三列值为1657411200(t_modified)
Xid=21,表示这个事务被正确提交了;
另外,还有⼀个参数binlog_row_image,默认值是FULL,这样的话在这个Delete_event⾥⾯就会包含了这个删掉⾏的所有字段的值;如果把这个参数值改为MINIMAL,则只会记录必要的信息,在这⾥的话也就是只⽤记录id=4即可;
从上⾯这些信息可以看到,当binlog_format的格式为row的时候,binlog⾥⾯记录了真实的删除⾏的信息,这样传到备库去的时候,也会去根据这个主键id来进⾏删除,所以不会有主备删除不⼀致的问题;
3.2.3 mixed
上⾯讲了binlog的两种格式了,不知道⼤家有没有发现,这两种格式都有各⾃的缺点:
- statement:因为记录的是逻辑的SQL语句,所以在执⾏的时候,可能会导致主备不⼀致的问题;
- row:因为记录的是删除的全部的真实数据,所以会很占空间的;
- ⽐如你delete掉10w⾏数据,那row格式的binlog中就会⾄少把这个10w⾏数据的id给保存下来;
- 既占⽤存储空间,也要耗费IO资源,影响SQL语句的执⾏速度;
- 如果使⽤的是statement格式,就写⼀⾏进去就⾏了;
因此,MySQL就采⽤了折中的⽅案:mixed;
- 当设置为mixed的时候,MySQL⾃⼰会判断⼀条SQL语句是否可能会导致主备不⼀致,如果可能导致则采⽤row格式,
- 否则就采⽤statement格式;这样的话,即可以使⽤到statement格式的数据简洁节约空间,也可以使⽤到row格式的数据正确性;
例如我们上⾯的示例:
mysql> delete from t where a>=4 and t_modified<='2022-07-10' limit 1;当是 mixed格式时,这⾥就会记录成row格式的;如果去掉limit 1,则会记录成statement格式的;
我们将 binlog_format改为 mixed格式,再来执⾏⼀条SQL语句:
binlog-format="ROW"
// 之后可⽤这个语句查看:
show variables like '%binlog_format%';
insert into t values(10,10, now());此时如果是 mixed 格式的话,MySQL会如何记录这条语句呢?(注意 now() 这个⽅法)
可能⼤家都会觉得,这个会记录成为row格式,因为这个 now()函数,不同时候执⾏的话,得出来的值是不同的,应该就得记录成 row;

但是根据binlog中的记录来看,它却记录的是statement格式的,那这样的话这个SQL语句在从库执⾏的数据不会不⼀致吗?
那再⽤mysqlbinlog⼯具来看看binlog⽇志中记录的详细信息:
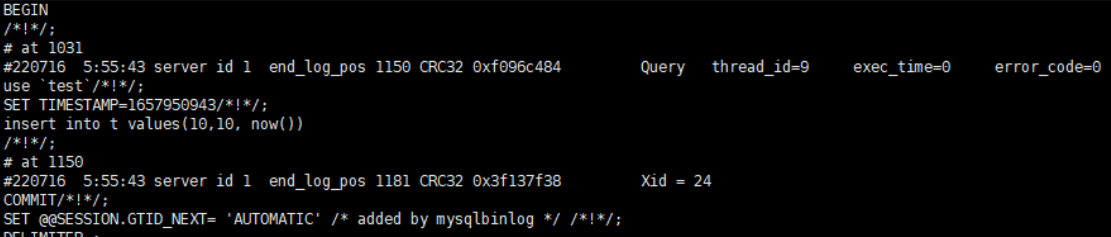
这⾥有个SETTIMESTAMP=1657950943,也就是说它在这⾥直接使⽤set命令设置好了接下⾥的now()函数执⾏时返回值;
这样的话,主从库的时间也就不会不⼀致了;
这⾥也说明了⼀个问题,当你要做数据恢复或者重放binlog数据时,不能在使⽤mysqlbinlog解析了⽇志之后,直接就复制⾥⾯的statement语句来执⾏,这样可能执⾏的结果会发⽣错误,因为它可能还会依赖于上下⽂的⼀些信息;
那么binlog恢复数据的标准做法,
- 使⽤mysqlbinlog⼯具解析出来,
- 找到你需要重放数据的开始位置(–start-position)和结束位置(–stop-position),
- 然后把解析结果发送给MySQL⾃⼰执⾏:
mysqlbinlog binlog.000008 --start-position=2738 --stop-position=2973 |
mysql -h127.0.0.1 -P13000 -u$user -p$pwd;最后,对于这binlog 的三个格式做⼀个总结:
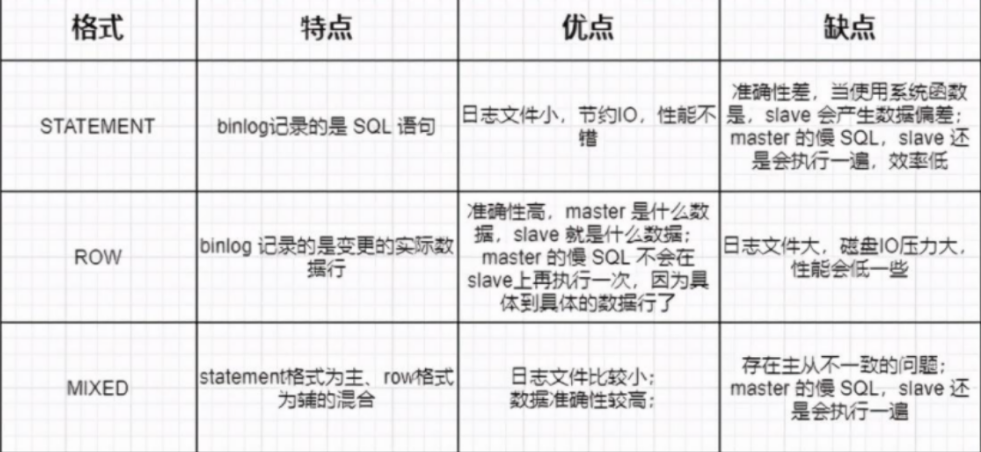
现在的话⼀般binlog格式是row(MySQL默认的也是row),因为这样做的直接好处就是数据恢复;

