MySQL的锁
1. MySQL 锁结构
我们前⾯讨论了对于当前读是需要通过加锁来实现的,那这个加锁,到底是加的⼀个什么锁呢?或者说这个锁的结构是什么样的
⾸先对于这样⼀条记录:

最开始它是没有锁的;
当⼀个事务想要对这条记录做编辑时,就得对这条记录进⾏加锁,这个加锁是通过⼀个与这条记录相关联的锁结构来实现的;
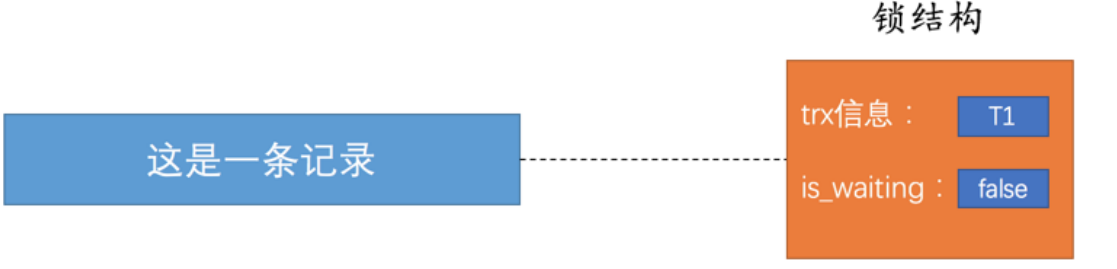
这个锁结构中内容很多,这⾥就只简略的提供了两个属性:
- trx信息:这个锁结构是哪个事务⽣成的,即是哪个事务加的这把锁;
- is_waiting:代表当前事务是否在等待,也就是说不是当前事务获取到锁能去执⾏任务;
加锁流程:
(在讲加锁流程之前,我们⼀定要知道,不管是去执⾏加锁和解锁,都是执⾏这个事务的线程去做的事情);
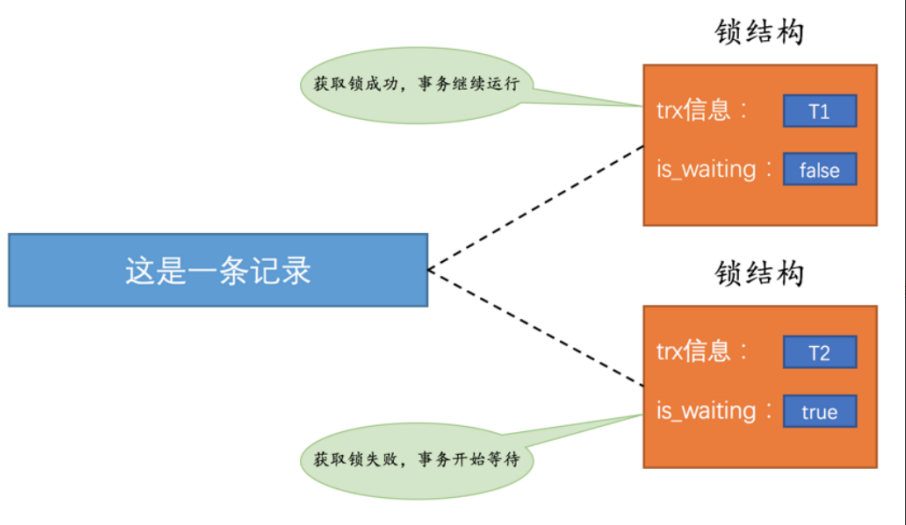
⾸先T1事务要改动这条记录,就去找有没有这条记录相关联的锁结构;
- 此时这条记录相关联的锁结构不存在,则需要⽣成⼀个锁结构来与这条记录相关联;
- 以前没有其他事务,所以is_waiting属性为false;
- 也就是说这个T1事务获取锁成功,那执⾏T1事务的线程,才可以继续执⾏后⾯的操作;
在T1事务执⾏的时候(未提交之前),T2事务也想要改动这条记录,同样也去看看有没有这条记录相关联的锁结构;
- 此时发现有⼀个锁结构,所以T2事务不能直接进⾏加锁;
- 但是它还是会⽣成⼀个锁结构与这条记录关联,不过锁结构的is_waiting属性为true,表示T2这个事务需要进⾏等待;(也就是执⾏T2事务的线程会被挂起阻塞)
- 也就是说这个T2事务获取锁失败,会进⾏等待;
到此时的图示⼤概为这个样⼦:
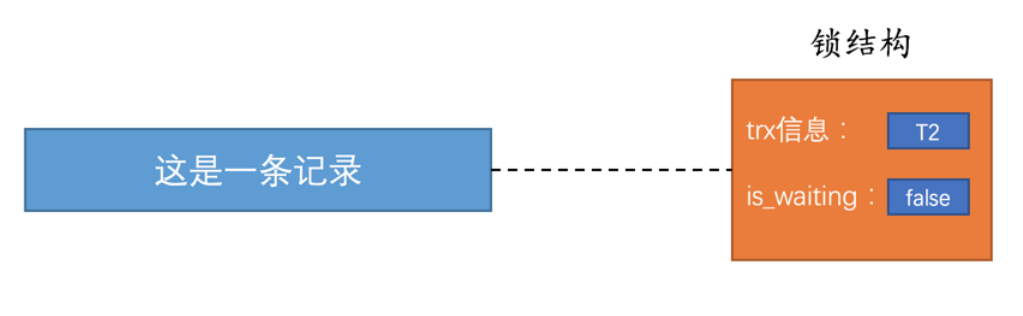
当T1事务提交之后,就会把它⽣成的锁结构给释放掉;然后看看还有没有其他事务在等待获取锁;
- 这⾥发现了还有T2事务在等待获取锁,所以就把T2事务对应的锁结构的is_waiting属性给改为false;
- 然后唤醒T2事务的线程,让它继续执⾏;
- 也就表示T2事务获取到了锁,可以继续执⾏后⾯的流程了;
此时的图示为:
总结⼀下:
当不加锁的时候,就不会存在对应的锁结构;
当加锁的时候,都会去⽣成对应的锁结构;
如果加锁成功了,is_waiting属性就是false;线程可以继续执⾏后⾯的任务;
如果加锁失败了,is_waiting属性就是true;线程会被挂起阻塞;
当前⼀个事务提交之后,会去检查如果还有事务在等待,则会唤醒执⾏等待事务的线程;
上⾯说到锁结构,是针对⼀条记录,如果⼀个事务对多条记录加锁,会创建多个锁结构吗?例如以下语句:
# 事务T1
SELECT * FROM t LOCK IN SHARE MODE;这个语句需要为表t的所有记录进⾏加锁,那会去为每条记录都⽣成⼀个对应的锁结构吗?
如果这个表中有10000条记录,那不就得⽣成10000个这样的锁结构?如果是这样这样的话,既会浪费存储空间,⼜会浪费创建锁时的开销;
InnoDB对于此的设计是,如果符合以下条件,就会把这些记录的锁放到⼀个锁结构中:
- 在同⼀个事务中进⾏的加锁操作;
- 被加锁的记录在同⼀个数据⻚中;
- 加锁类型是⼀样的;
- 等待状态是⼀样的;
示例图:
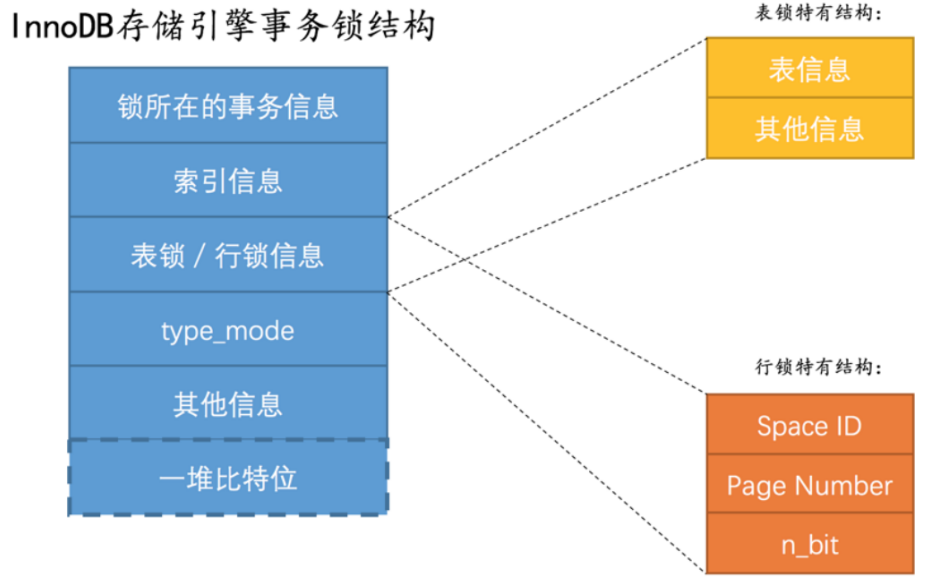
锁所在的事务信息:⼀个指针,指向了⽣成这个锁结构的事务;(可通过这个指针找到事务的全部信息)
索引信息:对于⾏锁,记录加锁的记录是哪个索引的;
表锁/⾏锁信息:
- 表锁:记录了对哪个表加锁,和⼀些其他信息;
- ⾏锁:记录了所在的表空间、数据⻚号、和⼀堆bit位:
- n_bit:对于⾏锁⽽⾔,⼀条记录就对应⼀个bit位,⼀个数据⻚中有多条记录,所以使⽤不同的bit位来区分到底是哪些记录加了锁;这个n_bit就代表了使⽤了多少bit位;
type_mode:⼀个32位的数,被分成了lock_mode、lock_type、rec_lock_type:
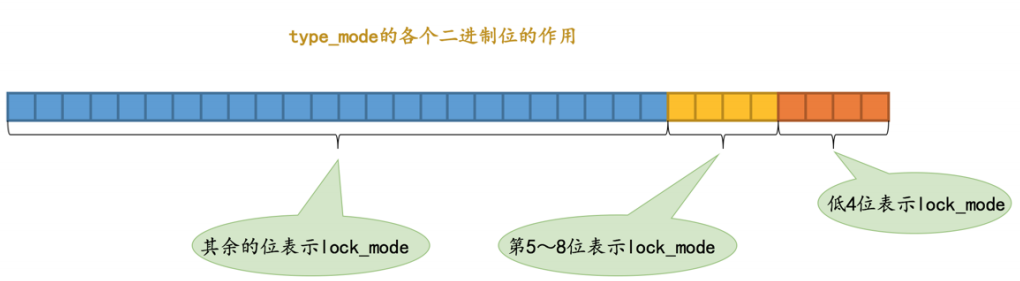
- lock_mode:占低4位,可选值也就是锁的类型:
- LOCK_IS(⼗进制的0):表示共享意向锁,也就是IS锁;
- LOCK_IX(⼗进制的1):表示独占意向锁,也就是IX锁;
- LOCK_S(⼗进制的2):表示共享锁,也就是S锁;
- LOCK_X(⼗进制的3):表示独占锁,也就是X锁;
- LOCK_AUTO_INC(⼗进制的4):表示 UTO-INC锁;
- InnoDB存储引擎中,LOCK_IS,LOCK_IX,LOCK_AUTO_INC都算是表级锁的模式,
- LOCK_S和LOCK_X既可以算是表级锁的模式,也可以是⾏级锁的模式
- lock_type:占5-8位,现在只⽤了第5、6为:
- LOCK_TABLE(⼗进制的16),也就是当第5个⽐特位置为1时,表示表级锁;
- LOCK_REC(⼗进制的32),也就是当第6个⽐特位置为1时,表示⾏级锁;
- rec_lock_type:占其他位,表示⾏锁的具体类型;(只有lock_type值为LOCK_REC时,这个字段才有值)
- LOCK_ORDINARY(⼗进制的0):表示next-key锁;LOCK_GAP(⼗进制的512):也就是当第10个⽐特位置为1时,表示gap锁;
- LOCK_REC_NOT_GAP(⼗进制的1024):也就是当第11个⽐特位置为1时,表示记录锁;
- LOCK_INSERT_INTENTION(⼗进制的2048):也就是当第12个⽐特位置为1时,表示插⼊意向锁;
- 其他的类型:还有⼀些不常⽤的类型;
- LOCK_WAIT(⼗进制的256):
- 当第9个⽐特位置为1时,表示is_waiting为true,也就是当前事务尚未获取到锁,处在等待状态;
- 当这个⽐特位为0时,表示is_waiting为false,也就是当前事务获取锁成功;
其他信息:⼀般就是为锁结构设计的⼀些哈希表和链表;
⼀堆⽐特位:如果是⾏锁结构的话,在该结构末尾还放置了⼀堆⽐特位,⽐特位的数量是由上⾯提到的n_bits属性表示的;
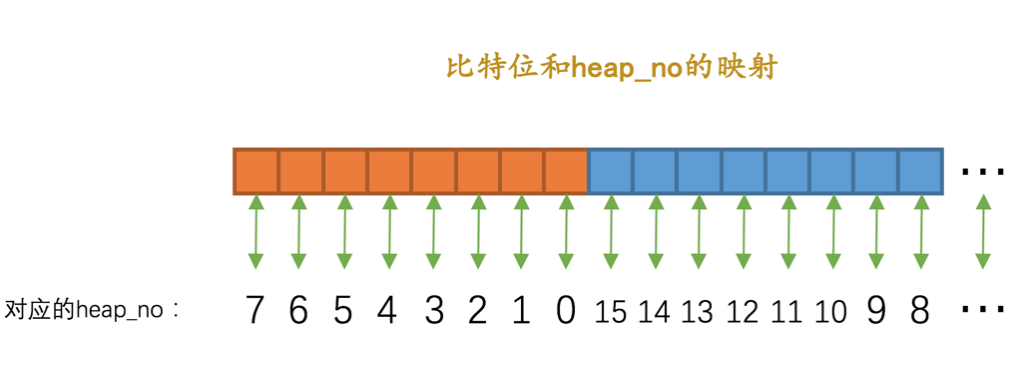
前⾯在讲数据⻚的物理结构时讲过⼀个heap_no的概念:

- 所以这⾥的⼀堆bit位和数据⻚中的⾏记录的映射关系就是通过heap_no来映射的
2. MySQL锁分类
2.1 ⾏级别共享锁和独占锁
- 共享锁(SharedLocks):简称S锁,即这个锁是可以共享的,可以类⽐Java读写锁中的读锁;在事务要读取⼀条记录时,需要先获取到S锁;
- 独占锁/排他锁(ExclusiveLocks):简称X锁,即这个锁是独占的,可以类⽐Java读写锁中的写;在事务要修改⼀条记录时,需要先获取到X锁;
| 兼容性 | X | S |
|---|---|---|
| X | 不兼容 | 不兼容 |
| S | 不兼容 | 兼容 |
示例:
- 事务T1获取到了⼀条记录的S锁:
- 事务T2如果是执⾏读取操作,则也需要去获取S锁,并且能够获取成功;
- 事务T2如果是执⾏编辑操作,则需要去获取X锁,此时会获取失败,并且线程被阻塞,直到事务T1将S锁释放掉;
- 事务T1获取到了⼀条记录的X锁:
- 事务T2不管是要去获取S锁还是X锁,都会获取失败,并且线程被阻塞,直到事务T1将S锁释放掉;
读操作加锁
对读取操作加S锁:
SELECT ... LOCK IN SHARE MODE;对读取操作加X锁:
SELECT ... FOR UPDATE;
对于写操作,即delete、update、insert 等操作:
- delete:先在主键索引的 B+树中定位到这条记录,然后去获取这条记录的X锁(即去创建锁结构);然后再去执⾏delete_mark操作,使得这条记录成为待删除记录;
- update:这个update有⼏种情况,但是我们没有必要去掌握那么细,只要知道 update 操作会获取X锁即可;(只是有些修改了主键id的update,需要先 delete,再insert)
- insert:insert操作不会显示地获取X锁,⽽是通过⼀种叫Gap锁的来实现。
2.2 表级别共享锁和独占锁
上⾯的锁都是针对⾏记录⽽⾔的,也就是⾏锁;
另外对于表也可以进⾏加锁,也就是表锁;
表锁同样可以先分为共享锁(S锁)和独占式(X锁),表锁的粒度⾃然⽐⾏锁要粗不少;
结合到对于⾏记录的影响来说:
- 事务T1获取到了⼀个表的S锁:
- 事务T2可以获取到这个表的S锁;
- 事务T3可以获取到这个表中记录的S锁;
- 事务T4不可以获取到这个表的X锁;
- 事务T5不可以获取到这个表中记录的X锁;
- 事务T1获取到了⼀个表的X锁:
- 事务T2不可以获取到这个表的S锁;
- 事务T3不可以获取到这个表中记录的S锁;
- 事务T4不可以获取到这个表的X锁;
- 事务T5不可以获取到这个表中记录的X锁;
其实到这⾥,跟上⾯的⾏级别锁的表现基本完全⼀样:
当⼀个事务获取到某个表的S锁之后,其他事务可以获取到这个表和表中记录的S锁,但是不能获取到表和表中记录的X锁;
当⼀个事务获取到某个表的X锁之后,其他事务都不可以获取到这个表和表中记录的S锁和X锁
这⾥说的是表级别锁对于⾏记录的影响,那么⾏记录对于表级别锁会不会有影响呢?
例如存在对于某个记录⾏加了X锁了,还可以对这个表加S锁或者X锁吗?
或者 存在对于某个记录⾏加了S锁了,还可以对这个表加X锁吗?
肯定是不⾏的,如果这样都⾏,就满⾜不了这些锁之间的互斥关系了;
但是如果不⾏,那在对于⼀个表加锁时,怎么知道这个表中有没有 ⾏记录 是已经加上锁了的呢?怎么也不可能⼀⾏⼀⾏的去遍历所有⾏吧,这样效率太慢了;
基于此,InnoDB设计出了意向锁(Intention Locks):
兼容性 X S IX 不兼容 不兼容 IS 不兼容 兼容 - 意向共享锁(Intention Shared Lock):简称IS锁;当事务准备在某⾏记录上加 S锁时,需要先在表级别加⼀个IS锁;
- 意向独占锁(Intention Exclusive Lock):简称 IX锁;当事务准备在某⾏记录上加X锁时,需要先在表级别加⼀个IX锁;
- 它们的兼容性与S锁和X锁相同;
示例:
- 事务T1要对表中记录⾏加S锁时,先对这个表加IS锁,然后才对记录⾏加S锁;
- 此时如果事务T2想对这个表加S锁,是可以直接加的;
- 但是如果事务T2想对这个表加X锁,就需要查看是否存在IS锁(或者IX锁了)了,如果存在,则需要等待IS锁释放掉之后才可以;
- 事务T1要对表中记录⾏加X锁时,先对这个表加IX锁,然后才对记录⾏加X锁;
- 此时如果事务T2相对这个表加S锁,先查看发现⼀家存在IX锁了,就需要等到IX锁释放掉之后才可以;
- 事务T2想对这个表加X锁也是同理;
也就是说IS锁和IX锁也是表级别的锁;它们的作⽤仅仅是为了在想要加表锁时,避免去遍历判断表中所有⾏记录是否存在锁,可以提升性能;
所有锁的兼容性为:
| 兼容性 | X | IX | S | IS |
|---|---|---|---|---|
| X | 不兼容 | 不兼容 | 不兼容 | 不兼容 |
| IX | 不兼容 | 兼容 | 不兼容 | 兼容 |
| S | 不兼容 | 不兼容 | 兼容 | 兼容 |
| IS | 不兼容 | 兼容 | 兼容 | 兼容 |
对于表级别的加锁,对应的操作为:
- 读操作:加S锁:LOCK TABLES t READ;
- 写操纵:加X锁:LOCK TABLES t WRITE;
- 其实可以发现,表级别的S锁和X锁 正常来说是没啥⽤的,因为不可能去使⽤这两个⼿动锁表的语句…
2.3 表级别的AUTO_INC锁
在使⽤ MySQL 的时候,应该⼤家都⽤过这个属性AUTO_INCREMENT,⼀般⽤于⽣成⾃增ID,例如这样⼀个表:
CREATE TABLE t (
id INT NOT NULL AUTO_INCREMENT,
c VARCHAR(100),
PRIMARY KEY (id) ) Engine=InnoDB CHARSET=utf8;当执⾏插⼊数据的时候,是可以不指定id的值的,MySQL内部会通过AUTO_INCREMENT来为id⽣成⾃增的值;
但是这个⾃增的时候,是需要对这个表进⾏加锁的;不然的话当多个事务同时执⾏插⼊时,就可能⽣成相同的id,这样去执⾏插⼊也是会失败的;
所以在执⾏插⼊语句的时候,对这个表加⼀个⾃增锁,然后为每⼀条待插⼊的记录的AUTO_INCREMENT修饰的列分配⼀个⾃增的值;然后在语句结束之后,再把这个锁释放掉;
跟上⾯的⾏锁表锁不同,它们都是事务级别的锁,即事务提交之后锁才会释放;
⽽这个⾃增锁,不是事务级别的,⽽是语句级别(甚⾄低于语句级别)的,它的设计有以下的历史:
MySQL5.0版本的时候,这个⾃增锁的范围是语句级别;
- 也就是说,如果⼀个语句申请了⼀个表的⾃增锁,这个锁会等到语句执⾏结束才会被释放;
- (这样显然是影响并发度的,因为语句后⾯还要去执⾏很多插⼊操作)
MySQL5.1.22版本引⼊了新策略,新增了⼀个参数innodb_autoinc_lock_mode(默认值是1)
当参数值为0:表示采⽤5.0版本的策略,即语句结束后才释放锁;(语句结束后释放的都会影响并发度)
当参数值为1:
- 普通的insert语句,在申请到⾃增锁之后,⻢上就释放;
- 类似insert…select这样批量插⼊的语句,⾃增锁会等到语句结束之后才被释放;
当参数值为2:所有的⾃增锁都是申请到之后,⻢上就释放;
这⾥可能⼤家会有点奇怪,为什么MySQL的默认值采⽤的是1⽽不是2呢?明显2⾥⾯所有的⾃增锁申请到之后就⻢上释放,对于插⼊性能来讲更好;
来看⼀下这个场景:
t表和t2表完全⼀样,都是⼀个⾃增的主键id和另外两个字段;
- sessionA先往t表中插⼊了4⾏数据;
- sessionB创建了t2表;
- sessionA和sessionB同时往t2表插⼊数据;(sessionB是从t表中select出来数据并进⾏插⼊的)
这⾥,假设是使⽤的innodb_autoinc_lock_mode=2,也就是申请到⾃增值之后⻢上就释放锁(未等到语句执⾏结束);那可能会出现这种情况:
- sessionB先插⼊了两条记录:(1,1,1)、(2,2,2)
- 然后执⾏sessionA的插⼊,并且申请⾃增id得到id=3,插⼊了(3,5,5);
- 然后sessionB继续执⾏插⼊,插⼊后⾯两条记录(4,3,3)、(5,4,4);
即此时:
- t表中数据为:(1,1,1)、(2,2,2)、(3,3,3)、(4,4,4);
- t2表中数据为:(1,1,1)、(2,2,2)、(3,5,5)、(4,3,3)、(5,4,4);
从这⾥逻辑上看可能并没有问题,因为没有要求说t2表中的所有数据必须跟t1表中相同;
但是我们前⾯讨论过binlog,当它的格式为statement时,它是要记录这些插⼊语句的;
那对于t2表的插⼊操作,它记录的binlog⽇志只有两种情况:
- 先记录sessionA,再记录sessionB;即结果为:(1,5,5)、(2,1,1)、(3,2,2)、(4,3,3)、(5,4,4)
- 先记录sessionB,再记录sessionA;即结果为:(1,1,1)、(2,2,2)、(3,3,3)、(4,4,4)、(5,5,5)
⽽此时主库中实际的数据为:(1,1,1)、(2,2,2)、(3,5,5)、(4,3,3)、(5,4,4);
也就是说,拿binlog⽇志到丛库中去执⾏时,⽆论是哪种情况,都会出现主备数据不⼀致;
(⽽出现这个问题的原因是:对于 sessionB 的 insert … select 语句,⽣成了 不连续的 id;当⽤statement格式的binlog来串⾏执⾏时,是没法做到顺序相同的)
上⾯是 假设使⽤的innodb_autoinc_lock_mode=2 ,那么按照 MySQL原本默认值innodb_autoinc_lock_mode=1 来看看是什么样;
当值为1时,对于insert … select这样批量插⼊的语句,⾃增锁会等到语句结束之后才被释放;
- 假设sessionB先执⾏,它去申请⾃增锁,申请到之后必须等到insert语句执⾏结束才会释放,则此时:
- sessionB执⾏完成,数据为:(1,1,1)、(2,2,2)、(3,3,3)、(4,4,4);
- 再去执⾏sessionA,执⾏完成后数据为:(1,1,1)、(2,2,2)、(3,3,3)、(4,4,4)、(5,5,5);
- 假设sessionA先执⾏,它也是申请⾃增锁,对于它是申请到之后⻢上就释放,但是它已经申请到了1了,则此时:
- sessionA执⾏完全,数据为:(1,5,5);
- 再去执⾏sessionB,执⾏完成后数据为:(1,5,5)、(2,1,1)、(3,2,2)、(4,3,3)、(5,4,4);
对于上⾯这种情况,哪个session先执⾏,binlog中就先记录哪个,前⾯说了:记录的binlog⽇志只有两种情况:
- 先记录sessionA,再记录sessionB;即结果为:(1,5,5)、(2,1,1)、(3,2,2)、(4,3,3)、(5,4,4)
- 先记录sessionB,再记录sessionA;即结果为:(1,1,1)、(2,2,2)、(3,3,3)、(4,4,4)、(5,5,5)
- 这样看来,主从库的数据也就是⼀致的了;
因此,MySQL默认采⽤了innodb_autoinc_lock_mode=1 ,即:
- 普通的 insert 语句,在申请到⾃增锁之后,⻢上就释放;
- 类似 insert … select 这样批量插⼊的语句,⾃增锁会等到语句结束之后才被释放;
当语句结束时才释放⾃增锁的话,就会得到完全连续的⾃增id,然后达到主从数据⼀致;
但是这样的话,⼜会将执⾏速度给变慢,因为得等insert语句完全执⾏结束;那有没有其他⽅法可以解决这个问题呢?
我们前⾯讲 binlog的格式时,还有⼀个格式叫做row,即在记录插⼊操作的时候,如实地记录完整的数据信息,你插⼊的数据是什么样就记录成什么样;
到从库去执⾏的时候,直接就使⽤记录的数据来插⼊,⽽不依赖⾃增主键去⽣成;那这样不就也能实现主从⼀致了
因此,在⽣产环境上,如果有 insert … select 这种批量插⼊语句(还有 replace … select、load data 等)的时候,建议设置参数为:
innodb_autoinc_lock_mode = 2
binlog_format = row
说了这么多,总结⼀下这个 表级别的⾃增锁AUTO_INC就是:
- 执⾏插⼊语句的时候 在表级别加⼀个 AUTO_INC锁,为每条待插⼊记录的 AUTO_INCREMENT 修饰的列都分配递增的id值;
- 然后分为两种锁:
- 语句级别锁:在insert语句执⾏结束之后,才释放这个锁;
- 其实这个的根本原因就是insert…select这种批量插⼊语句在执⾏之前是⽆法具体确定要插⼊多少条记录,所以等整个语句执⾏完才释放;
- 但是这样会锁住整个表,阻塞住后⾯要执⾏的依赖于⾃增锁的插⼊语句;
- 轻量级锁:在申请到⼀个列的⾃增值之后,就释放这个锁;
- 这样很快的就释放锁,不会让⼀个表⻓期的被锁住,可以提升插⼊性能;
- 但是在statement格式的binlog 下,可能出现主从数据不⼀致问题;
- 语句级别锁:在insert语句执⾏结束之后,才释放这个锁;
2.4 表级别的元数据锁(MDL)
MDL(metadata lock)是不需要显式地声明来使⽤的,在访问⼀个表的时候会被⾃动加上(系统默认加上),它的作⽤是:保证读写的正确性;
例如:
- ⼀个插⼊语句正在往表中按列插⼊数据,
- 在执⾏期间另⼀个线程对这个表结构做了变更,删除了⼀列,
- 那么这个插⼊语句跟表结果对不上,肯定就会出问题了;
所以在 MySQL5.5版本中引⼊了MDL:
- 当对⼀个表做增删改查时,会加MDL读锁;
- 当对⼀个表做结构变更时,会加MDL写锁;
它们之间的互斥关系为:
- 读锁之间不互斥,因此可以有多个线程同时对⼀张表做增删改查;
- 读写锁、写写锁之间是互斥的,⽤来保证变更表结构操作的安全性;
- 如果有两个线程同时要对⼀个表加字段,其中⼀个需要等另⼀个线程执⾏完成才能开始;
- 当有线程在对表中数据进⾏读取(也就是添加了读锁)时,如果另外线程要去更新表结构,也是需要等待那个线程执⾏完成释放读锁才⾏;
这⾥来看⼀个示例:

sessionA先启动⼀个事务,执⾏的是select操作,因此会对表t加⼀个MDL读锁,并且未提交事务;
sessionB再启动⼀个事务,也是执⾏select操作,也是对表t加MDL读锁,读读之间不互斥,因此可以正常加锁和正常执⾏;并且提交了事务;
sessionC再启动⼀个事务,执⾏的是alter操作,因此需要对表t加MDL写锁,但是sessionA的MDL读锁还未释放,所以sessionC这⾥会被阻塞;
sessionD再启动⼀个事务,执⾏的是select操作,因为需要加MDL读锁,但是前⾯sessionC的写锁请求还在那⾥阻塞着,因此sessionD的操作也会被阻塞;
即到现在为⽌,对于这个表的任何操作都不能执⾏了,对应线程都会被阻塞住,这个表完全不可能读写了;
如果这个表的查询是⽐较频繁那种,并且客户端有超时的重试机制,即当前⾯的线程被阻塞住且超时后,就会再启动⼀个session进⾏请求的话,整个MySQL应⽤的线程数很快就会爆满了,甚⾄直接打崩MySQL服务;
这⾥也可以看出,MySQL的MDL锁,是在语句执⾏开始时申请,但是语句执⾏结束后不会⻢上释放,⽽是等到事务提交后才会释放;
上⾯这个示例的问题 是因为 变更表结构导致的,那这个就可以引申出⼀个常⻅问题:如何安全地对⼀个表加字段?
⾸先需要解决⻓事务,因为MDL锁是在事务提交的时候才释放;如果是⻓事务⼀直不提交,则会⼀直占着MDL锁:
在MySQL的information_schema库的innodb_trx表中,你可以查到当前执⾏中的事务;
查看持续时间超过⼀定时间的事务:■
select * from information_schema.innodb_trx where TIME_TO_SEC(timediff(now(),trx_started))>60如果需要做DDL的表刚好有⻓事务执⾏,需要考虑先暂停DDL,或者直接kill掉这个⻓事务;
如果没有⻓事务,但是要操作的表是⼀个热点表,即请求很频繁的表,会被频繁添加MDL读锁;⽽⼜不得不做字段添加的操作:
- 这时候kill基本就没啥⽤了,因为新的请求⻢上就进来了;
- 因此可以在alter table语句⾥⾯设定等待时间:
- 如果在等待时间内能够拿到MDL写锁最好,如果拿不到就让它超时放弃并释放锁,不阻塞后⾯的业务语句;
- 之后,DBA可再通过重试命令来重复这个过程;
另外在MySQL5.6版本中⽀持了online ddl,它的操作过程是:
- 拿MDL写锁
- 降级成MDL读锁
- 真正做DDL
- 升级成MDL写锁
- 释放MDL
- 即
- 在拿到MDL写锁之后,先会降级成MDL读锁,减少对增删改查操作的阻塞时间;
- 然后去做DDL,这⾥的DDL是通过类似copytable的⽅式,也就是复制⼀张表出去,在那张表上做DDL操作,因此是不影响原表的,所以可以允许对于原表做增删改查等操作;
- 最后,需要把复制的表rename成原表的名字时,这个时候就⼜需要升级为MDL写锁了,阻塞住其他对于原表的操作;
2.5 间隙锁(gap)+ next-key lock
关于间隙锁和next-key lock的东⻄⾮常⾮常多,也很复杂,需要⾃⼰去深⼊思考和分析每⼀种情况
这里建议MySQL45讲
- 20 | 幻读是什么,幻读有什么问题?
- 21 | 为什么我只改一行的语句,锁这么多?
3. 死锁
最后再说⼀下死锁,我们先介绍⼀下死锁的整体概念,这个其实适⽤于所有的死锁的解释:
- 死锁发生条件(破坏一个即可避免死锁):
- 互斥:共享资源同一时间只能被单个线程访问
- 占有且等待:一个线程在访问资源A等待资源B时,一直持有资源A(占住不放)
- 不可剥夺:其它线程不能强行剥夺当前线程占有的资源(只能自己主动释放)
- 循环等待:线程T1等待线程T2占用的资源,线程T2等待线程T1占用的资源(你等我我等你)
- 破坏死锁(需考虑实现成本):
- 互斥:不可破坏,锁的目的就是互斥共享资源访问
- 占有且等待:
- 方法一:创建进程时,要求它申请所需的全部资源,系统或满足其所有要求,或什么也不给它。这是所谓的 “ 一次性分配”方案。
- 方法二:要求每个进程提出新的资源申请前,释放它所占有的资源。这样,一个进程在需要资源S时,须先把它先前占有的资源R释放掉,然后才能提出对S的申请,即使它可能很快又要用到资源R。
- 不可剥夺:破坏“不可剥夺”条件就是允许对资源实行抢夺
- 方法一:如果占有某些资源的一个进程进行进一步资源请求被拒绝,则该进程必须释放它最初占有的资源,如果有必要,可再次请求这些资源和另外的资源。
- 方法二:如果一个进程请求当前被另一个进程占有的一个资源,则操作系统可以抢占另一个进程,要求它释放资源。只有在任意两个进程的优先级都不相同的条件下,方法二才能预防死锁。
- 循环等待:破坏“循环等待”条件的一种方法,是将系统中的所有资源统一编号,进程可在任何时刻提出资源申请,但所有申请必须按照资源的编号顺序(升序)提出。这样做就能保证系统不出现死锁。
我们这⾥看⼀下关于MySQL的⾏锁产⽣死锁的示例:

- 事务A启动⼀个事务,执⾏update操作,whereid=1因此会对id=1这⾏数据加锁;
- 事务B启动⼀个事务,执⾏update操作,whereid=2因此会对id=2这⾏数据加锁;
- 事务A⼜去执⾏updateid=2的操作,需要获取id=2这⾏数据的X锁;但是事务B持有这⾏数据的X锁,因此事务A在这⾥会被阻塞住;
- 事务B⼜去执⾏updateid=1的操作,需要获取id=1这⾏数据的X锁;但是事务A持有这⾏数据的X锁,因此事务B在这⾥会被阻塞住;
也就是说,在这个时候:
- 事务A持有id=1的锁,并且等待事务B释放id=2的锁;
- 事务B持有id=2的锁,并且等待事务A释放id=1的锁;
- 当没有外⼒作⽤的情况下,谁都会不会先释放,因此陷⼊了循环等待,也就是发⽣了死锁;
前⾯说过,要破坏死锁,可以破坏那三个条件:占有且等待、不可剥夺、循环等待;
MySQL中为了解决死锁的场景,它设计了两种策略:
- 出现死锁后,有⼀个超时参数innodb_lock_wait_timeout,即当等待了这么⻓时间之后还未获取到资源,就释放⾃⼰持有的锁;
- 这个参数默认值为50s,即当出现死锁之后,第⼀个锁住的线程需要等待50s才能超时退出,对于正常服务⽽⾔,这个时间是不可能接受的;
- 但是⼜不可能把这个参数设置成⼀个很⼩的值,⽐如1s;这样如果是正常的锁等待,也会发⽣频繁超时,被误伤从⽽导致不能正常允许;
- 所以⼀般情况不采⽤这个策略;
- 主动死锁检测,由参数innodb_deadlock_detect控制,这个死锁检测在检测到发⽣了死锁之后,能够快速地主动回滚死锁链条中的某⼀个事务,让其他事务可以继续执⾏;
- 这个参数默认值为on,也就是默认打开主动死锁检测;
- 只是这个主动死锁检测是有⼀定的额外负担的;
- 因为每个新进来被阻塞的现场,都要判断会不会由于⾃⼰的加⼊导致了死锁,它需要和其他所有线程去⽐较判断,单个线程的时间复杂度为O(n);
- 如果有1000个并发线程同时更新同⼀⾏,则死锁检测就会执⾏1000*1000=100w次;这期间就会消耗⼤量的CPU资源;
- 要解决这个问题,可能就需要改MySQL源码,去限制⼀定的并发数之类的,我们就不去研究这个了;
思考⼀下,这两种⽅式是破坏了什么条件来解决死锁的呢?
- 超时参数:破坏占有且等待条件;
- 死锁检测:破坏不可剥夺条件;

